هوش مصنوعی دیگر صرفاً واژهای علمی در سرفصلهای دانشگاهی یا ابزاری در دست پژوهشگران نیست؛ اکنون به بطن تجربهی روزمره ما نفوذ کرده و آن را دگرگون میسازد. در این میان، شرکت متا با عرضهی نسل چهارم مدلهای زبان بزرگ خود با نام لاما 4 (Llama 4)، گام بلندی به سوی آیندهای برداشته که در آن، هوش مصنوعی نهتنها دقیقتر و خلاقتر، بلکه انسانمحورتر است. آنچه این مدلها را (اسکاوت (Scout)، ماوریک (Maverick)، ریزنینگ (Reasoning) و بهیمث (Behemoth)) از دیگر رقبا متمایز میسازد، نه فقط توان پردازشی یا حجم پارامترهای هوش مصنوعی، بلکه نگاه نوین به ترکیب تخصصها، معماری هوش مصنوعی چندوجهی و پیوند نزدیک با محصولات مصرفی است؛ از واتساپ گرفته تا Meta.ai.
این نوشتار به بررسی جامع و موشکافانهی خانوادهی Llama 4 میپردازد؛ از Scout سبکوزن و سریع گرفته تا Behemoth سنگینوزن و توانمند. در این میان، با نگاهی تحلیلی به معماری MoE، ساختار متن باز، فرآیند آموزش و اهداف کلان متا، تصویری روشن از آیندهی مدلهای زبانی ترسیم میشود. آیندهای که رقابت در آن دیگر تنها بر سر قدرت خام نیست، بلکه بر سر درک، تعامل و اثرگذاری واقعی در زندگی انسانها است.
فهرست مطالب
قابلیتهای متا 4
شرکت متا در تاریخ ۵ آوریل ۲۰۲۵ از جدیدترین نسل مدلهای هوش مصنوعی خود با نام لاما ۴ رونمایی کرد. این مجموعه شامل چهار مدل مجزا به نامهای اسکاوت (Scout)، ماوریک (Maverick)، ریزنینگ (Reasoning) و بهیمث (Behemoth) است که با تمرکز بر قابلیتهای هوش مصنوعی چندوجهی و بهینهسازی کارایی محاسباتی طراحی شدهاند. این مدلها از معماری نوآورانه ترکیب متخصصان (MoE) بهره میبرند که به آنها امکان میدهد وظایف پیچیده را به زیروظایف کوچکتر تقسیم کرده و هر زیروظیفه را به یک جزء تخصصی واگذار کنند. این رویکرد منجر به بهبود عملکرد کلی و کاهش هزینههای محاسباتی مورد نیاز برای آموزش و اجرا میشود.

در حال حاضر، مدلهای اسکاوت و ماوریک به طور عمومی از طریق پلتفرمهای متا و هاگینگ فیس در دسترس هستند، در حالی که مدل بهیمث هنوز در حال توسعه است. مدل اسکاوت با ۱۰۹ میلیارد پارامتر در پردازش اسناد متنی طولانی با پنجره کانالی تا ۱۰ میلیون توکن عملکرد برجستهای دارد. مدل ماوریک با ۴۰۰ میلیارد پارامتر برای کاربردهای دستیار هوشمند عمومی، تولید محتوای خلاقانه و وظایف چندزبانه بهینه شدهاست. انتظار میرود مدل بهیمث قدرتمندترین مدل متا با کاربردهایی در حوزههای STEM باشد.
شرکت متا مدل لاما ۴ را در دستیار هوش مصنوعی خود در برنامههای واتساپ، مسنجر و اینستاگرام در ۴۰ کشور ادغام کردهاست، اما قابلیتهای چندوجهی آن فعلاً محدود به کاربران انگلیسیزبان در ایالات متحده است. این شرکت همچنین به دلیل نگرانیهای قانونی در اتحادیه اروپا با محدودیتهای صدور مجوز مواجهاست و این قابلیت در زمان انتشار مقاله برای کاربران ایرانی در دسترس نبودهاست. عرضه لاما ۴ واکنش متا به رقابت با شرکتهایی مانند OpenAI و DeepSeek است و در حالی که در برخی وظایف عملکرد بهتری نشان میدهد، در زمینههایی مانند استدلال منطقی از رقبای پیشرفتهتر عقبتر است. با این حال، متا این عرضه را سرآغاز مرحله جدیدی در توسعه هوش مصنوعی لاما میداند و بر تعهد خود به پیشبرد هوش مصنوعی متنباز تأکید میکند.

معماری مدل هوش مصنوعی لاما 4
در حوزه مدلهای هوش مصنوعی پیشرفته، شرکت متا از رویکرد نوینی در طراحی مدلهای زبانی بزرگ خود، تحت عنوان لاما ۴، پرده برداشتهاست. این مدلها، که با نامهای لاما ۴ اسکاوت و لاما ۴ ماوریک شناخته میشوند، از معماری ترکیب متخصصان (Mixture of Experts – MoE) بهره میبرند. ویژگی بارز این معماری آن است که در پردازش هر ورودی خاص، تنها بخش محدودی از کل پارامترهای مدل فعال میگردد. این سازوکار هوشمندانه منجر به کاهش چشمگیر سربار محاسباتی مورد نیاز برای اجرای مدل میشود.
بر اساس اعلام شرکت متا، نسل جدید مدلهای لاما برای نخستین بار قادر به درک و پردازش همزمان دادههای متنی و تصویری در قالب یک معماری یکپارچه هستند. این شرکت خاطرنشان کردهاست که این مدلها با استفاده از حجم وسیعی از دادههای تصویری و ویدئویی آموزش دیدهاند تا قابلیت درک بصری گستردهای را کسب نمایند. در مرحله پیشآموزش، این سیستم توانایی پردازش همزمان تا ۴۸ تصویر را داشتهاست. همچنین، نتایج ارزیابیهای انجام شده پس از مرحله آموزش نشان میدهد که این مدلها عملکرد قابل توجهی را با دریافت حداکثر هشت تصویر به عنوان ورودی از خود نشان میدهند.

لاما ۴ اسکاوت: انجام وظایف چندرسانهای با یک کارت گرافیک
در ادامه معرفی مدلهای هوش مصنوعی لاما ۴، به بررسی مدل لاما ۴ اسکاوت میپردازیم که به عنوان مدل کوچکتر در این خانواده معرفی شدهاست. این مدل از مجموع ۱۰۹ میلیارد پارامتر موجود، بهطور فعال از ۱۷ میلیارد پارامتر استفاده میکند که این پارامترها در بین ۱۶ متخصص مختلف توزیع شدهاند. لاما ۴ اسکاوت به گونهای بهینهسازی شدهاست که بتواند بر روی یک واحد پردازش گرافیکی H100 اجرا شود. هدف از طراحی این مدل، انجام وظایف متنوعی نظیر پردازش متون طولانی، پاسخگویی به پرسشهای مرتبط با تصاویر، تحلیل و بررسی کدهای برنامهنویسی و همچنین درک و تحلیل همزمان چند تصویر است.
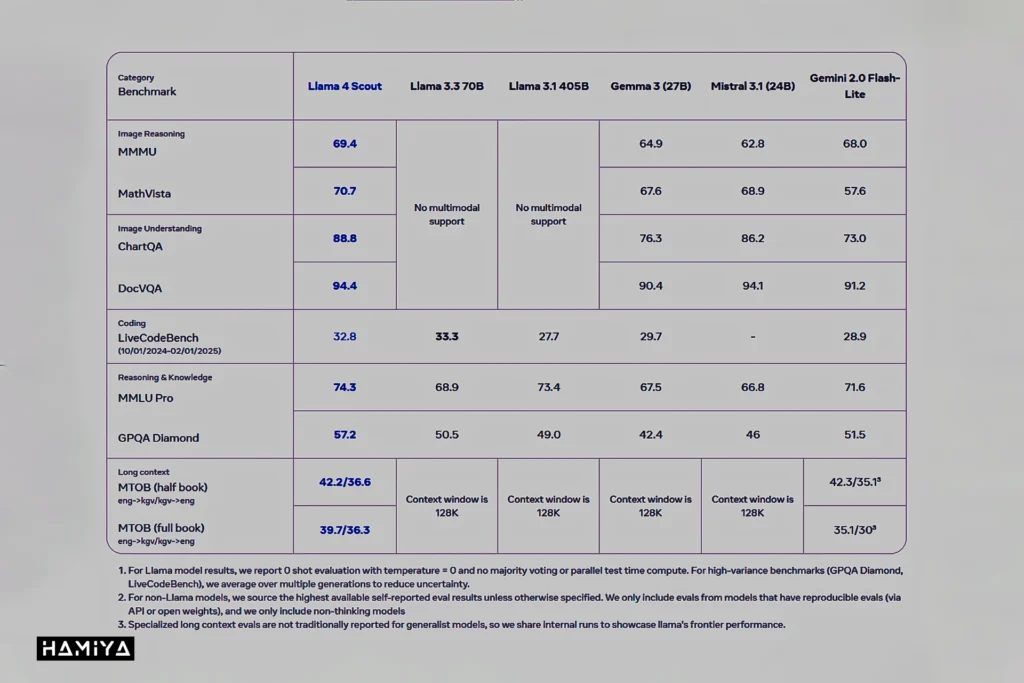
یکی از ویژگیهای برجسته مدل اسکاوت، پنجره کانالی بسیار وسیع آن است که به ۱۰ میلیون توکن میرسد! تقریباً معادل ۵ میلیون کلمه یا بیشتر. در حالی که این مقیاس قابل توجهاست، شرکت متا توضیحات دقیقی در مورد چگونگی پردازش مؤثر پرسشهای پیچیده فراتر از جستجوهای ساده کلمات در این حجم وسیع از متن ارائه نکردهاست. استفاده این شرکت از معیار قدیمی “سوزن در انبار کاه” برای ارزیابی عملکرد پنجره کانالی، محدودیتهایی را نشان میدهد، به ویژه با توجه به وجود معیارهای پیشرفتهتر و جامعتر برای این منظور. شایان ذکر است که تمامی مدلهای زبانی، همچنان در زمینه درک عمیق و یکپارچه متن و تصویر با محدودیتهایی مواجه هستند.
علاوه بر این، لازم به ذکر است که مدل لاما ۴ اسکاوت در مراحل پیشآموزش و پسآموزش تنها با طول متن ۲۵۶ هزار توکن آموزش دیدهاست. بنابراین، پنجره کانالی ۱۰ میلیون توکنی که به عنوان یکی از قابلیتهای این مدل تبلیغ میشود، بر اساس تعمیم طول دنبالهها به دست آمدهاست و نه از طریق آموزش مستقیم با چنین طول متنی. این بدان معناست که مدل توانایی کار با متنهای طولانیتر را دارد، اما این توانایی به طور مستقیم در طول فرآیند آموزش به آن داده نشدهاست.
ارتقاء عملکرد و مقیاسپذیری با لاما ۴ ماوریک
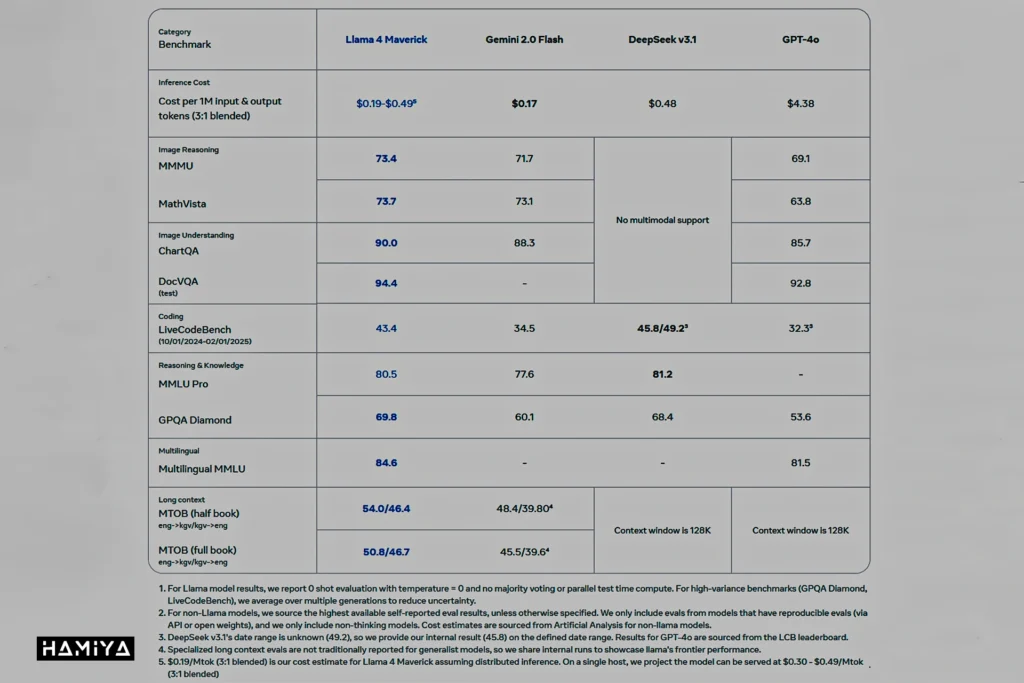
در ادامه معرفی مدلهای لاما ۴، به بررسی مدل لاما ۴ ماوریک میپردازیم که با هدف گسترش مقیاسپذیری و بهبود عملکرد طراحی شدهاست. این مدل نیز همانند مدل اسکاوت از ۱۷ میلیارد پارامتر فعال استفاده میکند، اما در مجموع از ۴۰۰ میلیارد پارامتر بهره میبرد که در بین ۱۲۸ متخصص مختلف توزیع شدهاند. لاما ۴ ماوریک نیز از معماری ترکیب متخصصان استفاده میکند که با فعالسازی تنها زیرمجموعهای از این متخصصان برای پردازش هر ورودی، به کاهش سربار محاسباتی کمک میکند. با وجود این افزایش کارایی، به دلیل ابعاد بزرگ این مدل، استقرار آن همچنان نیازمند یک سرور کامل مجهز به واحدهای پردازش گرافیکی H100 است. این مدل از پنجرههای متنی با ظرفیت حداکثر یک میلیون توکن پشتیبانی میکند.
شرکت متا گزارش دادهاست که مدل لاما ۴ ماوریک در چندین ارزیابی معیار، عملکرد بهتری نسبت به مدلهای پیشرویی نظیر GPT-4o از شرکت OpenAI و Gemini 2.0 Flash از شرکت Google از خود نشان دادهاست. همچنین، این مدل در وظایف مربوط به استدلال و تولید کد، نتایجی مشابه مدل Deepseek-V3 کسب کردهاست، این در حالی است که ماوریک از کمتر از نیمی از تعداد پارامترهای فعال مورد استفاده در Deepseek-V3 بهره میبرد. در پیکربندی آزمایشی چت خود، مدل ماوریک موفق به کسب امتیاز ۱۴۱۷ در رتبهبندی LMArena ELO شدهاست که نشاندهنده عملکرد رقابتی آن در مقایسه با سایر مدلهای زبانی بزرگ است.
شایان ذکر است که هر دو مدل “لاما ۴ اسکاوت” و “لاما ۴ ماوریک” به عنوان مدلهای با وزن باز از طریق وبسایت llama.com و پلتفرم Hugging Face در دسترس عموم قرار گرفتهاند. علاوه بر این، شرکت متا این مدلها را در محصولات مختلف خود از جمله واتساپ، مسنجر، اینستاگرام دایرکت و Meta.ai ادغام کردهاست، که این امر نشاندهنده اهمیت و کاربردی بودن این مدلها در محصولات و خدمات این شرکت است. انتظار میرود که مدلهای بیشتری از خانواده لاما ۴ در رویداد LlamaCon که در تاریخ ۲۹ آوریل برگزار خواهد شد، معرفی گردند. لازم به ذکر است که استفاده از این مدلها در برنامههای کاربردی متا نظیر اینستاگرام، واتسآپ و غیره در تاریخ انتشار مقاله برای کابران ایرانی ممکن نیست.
مدل بهیمث نقش معلم را در مدلهای لاما ۴ ایفا میکند.
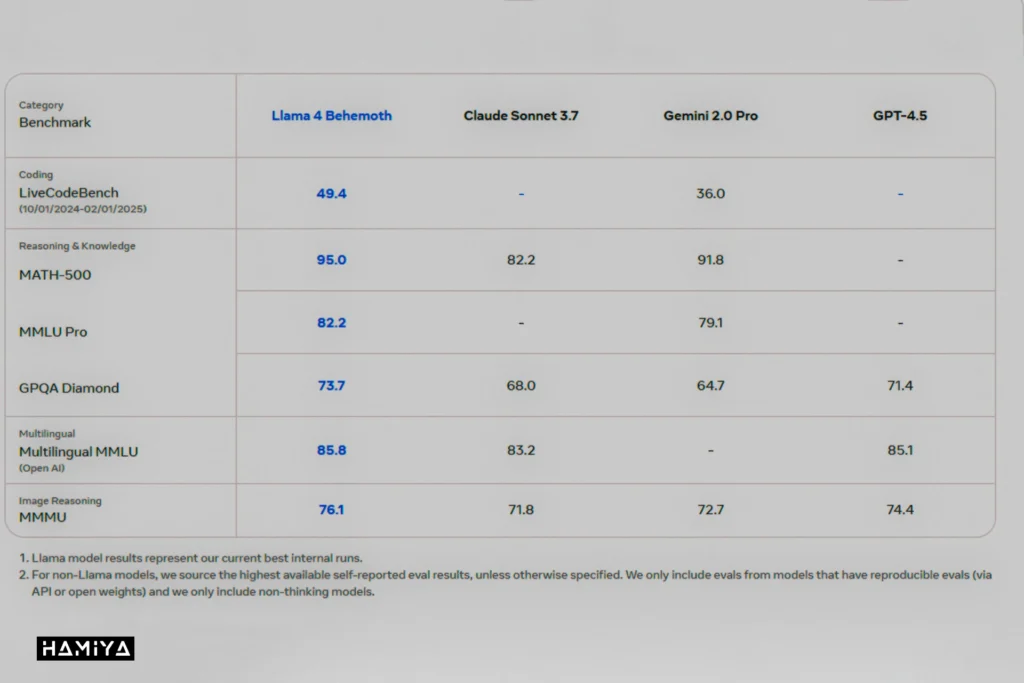
در فرآیند توسعه مدلهای لاما ۴ اسکاوت و ماوریک، شرکت متا از یک مدل داخلی بسیار بزرگتر به نام لاما ۴ بهیمث بهره بردهاست. این مدل عظیم دارای ۲۸۸ میلیارد پارامتر فعال از مجموع ۲ تریلیون پارامتر است که در میان ۱۶ متخصص توزیع شدهاند. لاما ۴ بهیمث به عنوان یک مدل معلم عمل میکند، به این معنا که از قابلیتهای پیشرفته آن برای آموزش و بهبود عملکرد مدلهای کوچکتر استفاده شدهاست. بر اساس گزارشهای منتشر شده از سوی متا، بهیمث در ارزیابیهای مربوط به معیارهای ریاضی و علمی، عملکرد بهتری نسبت به مدلهای برجستهای نظیر GPT-4.5، Claude Sonnet 3.7 و Gemini 2.0 Pro از خود نشان دادهاست.
با این حال، شرکت متا هنوز مقایسهای بین عملکرد مدل لاما ۴ بهیمث و مدل جدیدتر Gemini 2.5 Pro از شرکت گوگل، که در حال حاضر در ارزیابیهای مربوط به استدلال پیشتاز است، منتشر نکردهاست. مدل بهیمث همچنان در مراحل آموزش قرار دارد و انتظار میرود در آینده نزدیک به طور رسمی منتشر شود. همچنین، تاکنون یک مدل اختصاصی از خانواده لاما که به طور خاص برای وظایف استدلال طراحی شده باشد، منتشر نشدهاست، اگرچه آقای مارک زاکربرگ، مدیرعامل شرکت متا، در ماه ژانویه اشاره کرده بود که چنین مدلی در دست توسعهاست.
پس از اتمام مرحله پیشآموزش، شرکت متا مجموعهای از مراحل پسآموزش را به منظور بهبود عملکرد نهایی مدلهای خود اعمال میکند. این مراحل شامل تنظیم دقیق نظارت شده با استفاده از نمونههای آموزشی با کیفیت و گزینش شدهاست. در ادامه، از روش یادگیری تقویتی آنلاین با بهرهگیری از یک سیستم ناهمزمان جدید استفاده میشود که بر اساس گزارشها، کارایی فرآیند آموزش را تا ده برابر افزایش میدهد. این رویکرد چند مرحلهای در پسآموزش، به ارتقای دقت، انسجام و قابلیتهای کلی مدلهای لاما ۴ کمک شایانی میکند.
در ادامه فرآیند پسآموزش، از روش بهینهسازی مستقیم ترجیحات (Direct Preference Optimization) به منظور بهبود کیفیت خروجی مدلها استفاده میشود. در این روش، تمرکز ویژهای بر حذف مثالهای ساده و غیرضروری از مجموعه دادههای آموزشی قرار میگیرد. بر اساس اعلام متا، بیش از نیمی از دادههای آموزشی مدل ماوریک و ۹۵ درصد از دادههای آموزشی مدل بهیمث فیلتر شدهاند تا این مدلها بتوانند بر روی وظایف دشوارتر و پیچیدهتر تمرکز نمایند. این امر به ارتقای توانایی مدلها در حل مسائل چالشبرانگیز کمک میکند.
محرومیت اتحادیه اروپا از استفاده از مدلهای چندرسانهای لاما ۴
شرکت متا مدلهای لاما ۴ را تحت مجوز استاندارد خود برای لاما منتشر میکند، اما با اعمال یک محدودیت جدید و قابل توجه: سازمانها و افرادی که در کشورهای عضو اتحادیه اروپا مستقر هستند، مجاز به استفاده از مدلهای چندوجهی این مجموعه نخواهند بود! لازم به ذکر است که این محدودیت شامل کاربران نهایی این مدلها نمیشود و صرفاً توسعهدهندگان و شرکتهای مستقر در اتحادیه اروپا را در بر میگیرد.

به گفته نمایندگان شرکت متا، این تصمیم در پاسخ به “عدم قطعیتهای نظارتی” موجود در خصوص قانون هوش مصنوعی اتحادیه اروپا اتخاذ شدهاست. این اقدام نشاندهنده وجود تنشهای جاری میان شرکت متا و سیاستگذاران اتحادیه اروپا در زمینه تنظیم مقررات مربوط به هوش مصنوعی است. به نظر میرسد که متا با این اقدام، بسته به نوع تفسیر قوانین، خواستار دریافت راهنماییهای شفافتر یا اعمال مقررات کمتر محدودکننده در این حوزه است.
علاوه بر محدودیتهای اعمال شده برای اتحادیه اروپا، توسعهدهندگان در سایر نقاط جهان نیز ملزم به رعایت شرایط خاصی هستند. آنها باید برچسب قابل مشاهده “ساخته شده با لاما” را در محصولات و خدمات خود نمایش دهند و تنها مجاز به استفاده از نامهایی برای مدلهای خود هستند که با پیشوند “لاما” آغاز میشوند. همچنین، پلتفرمهایی که بیش از ۷۰۰ میلیون کاربر فعال ماهانه دارند، برای استفاده از این مدلها نیازمند دریافت مجوز ویژه از شرکت متا خواهند بود. این شرایط نشاندهنده رویکرد محتاطانه متا در انتشار و نظارت بر نحوه استفاده از مدلهای پیشرفته هوش مصنوعی خود است.
جمع بندی
در پرتو آنچه در این مقاله آمد، روشن است که Llama 4 نه صرفاً ادامهای بر نسلهای پیشین، بلکه گامی کیفی در عرصهی مدلهای زبان بزرگ بهشمار میرود؛ تلاشی هوشمندانه از سوی متا برای تلفیق عمق علمی با کاربردپذیری فراگیر. از طراحی معماری مبتنی بر ترکیب متخصصان (MoE) گرفته تا توجه ویژه به چندوجهیبودن، تعاملپذیری و سازگاری با بسترهای گستردهای چون اینستاگرام و مسنجر، همگی نشان از رویکردی نوین دارند که هدف آن، خلق مدلی انسانیتر، بازتر و متناسب با نیازهای واقعی کاربران در جهان امروز است.
اگر این مقاله توانسته باشد تصویری دقیق، منسجم و تحلیلی از Llama 4 ارائه دهد، رسالت خود را به انجام رساندهاست. ما نویسندگان ژورنال هامیا کوشیدیم تا نهتنها مشخصات فنی و معماری این مدلها را در همان لحظه انتشار مدل لاما 4 واکاوی کنیم، بلکه جایگاه آنها را در میدان رقابت هوش مصنوعی نیز بهدرستی تبیین نماییم. بیتردید، آیندهی هوش مصنوعی بهسوی مدلی انسانیتر، مسئولانهتر و آزادانهتر در حرکت است و Llama 4، با تمام چالشها و امیدهایش، گامی مؤثر در این مسیر خواهد بود.
سوالات متداول
Llama 4 نسل جدید مدلهای زبان بزرگ شرکت متا است که شامل چندین مدل تخصصی مانند Scout، Maverick و Behemoth میشود و با بهرهگیری از معماری ترکیب متخصصان (MoE) طراحی شدهاست.
این مدلها با توانایی پردازش چندرسانهای، پنجره کانالی وسیع و بهینهسازی هزینههای محاسباتی، عملکرد بالا در وظایف متنی و تصویری را به نمایش میگذارند.
Llama 4 در محصولات متا نظیر واتساپ، مسنجر، اینستاگرام و Meta.ai به کار گرفته میشود و برای تولید محتوا، تحلیل متون طولانی و پردازش تصاویر و ویدئوها بهینه شدهاست.
به دلیل نگرانیهای قانونی در حوزه هوش مصنوعی، استفاده از نسخههای چندرسانهای Llama 4 برای توسعهدهندگان کشورهای عضو اتحادیه اروپا محدودیتهایی دارد.
معماری MoE به مدل اجازه میدهد تا وظایف پیچیده را به زیروظایف تقسیم کند و هر بخش را توسط متخصصین مجزا پردازش نماید، که منجر به کاهش سربار محاسباتی و بهبود عملکرد کلی میشود.
در حالی که Llama 4 در برخی زمینهها عملکرد بهتری دارد، بهویژه در پردازش متون طولانی و چندرسانهای، در حوزههایی مانند استدلال منطقی نسبت به برخی رقبا هنوز چالشهایی باقی ماندهاست.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️