
رقابت بر سر رهبری در مرزهای پیشرفت مدلهای زبانی بزرگ (LLM) هرگز متوقف نمیشود؛ عرصهای که هر جهش فنی، معادلات بهرهوری و ارزش اقتصادی را از نو ترسیم میکند. پس از عرضه مدل توانمند Gemini 3 از سوی گوگل که توجه بسیاری از محققان و توسعهدهندگان را به خود جلب کرد، شرکت OpenAI با رونمایی قاطعانه از GPT 5.2، واکنشی سریع و تعیینکننده به نبض بازار نشان داد. این مدل نه صرفاً یک بهروزرسانی در قدرت محاسباتی، بلکه ابزاری استراتژیک و حیاتی برای کارهای حرفهای دانشمحور که طراحی شده تا با ارائه کارایی بیسابقه، فصلی نوین در اتوماسیون وظایف پیچیده بگشاید. در نگرش نویسندگان هامیا ژورنال، سرعت نوآوری و رقابت فزاینده، در نهایت به نفع مصرفکننده و پیشرفت عمومی است و مدل GPT-5.2 مصداق بارز یک محصول پیشرو است که برای آزادسازی پتانسیل اقتصادی افراد و سازمانها ساخته شده است.

مقاله حاضر، تحلیلی عمیق و کمی از قابلیتهای مدل GPT 5.2 است که فراتر از ادعاهای تبلیغاتی، به بررسی عملکرد آن در برابر سختترین سنجههای صنعتی میپردازد. مدل جدید با ثبت رکوردهای درخشان در معیارهای تخصصی نظیر GDPval برای ارزیابی وظایف مدیریتی و SWE-Bench Pro در مهندسی نرمافزار، گواهی بر این مدعاست که اکنون میتوان با سرعتی بیش از ۱۱ برابر و با هزینهای کمتر از ۱% یک متخصص انسانی، به خروجیهایی در سطح متخصص یا بالاتر دست یافت. در ادامه، این متن تخصصی جزئیات معماری هوش عاملی، برتری مدل در استدلال در محتوای طولانی تا ۲۵۶ هزار توکن و بهبود چشمگیر ۳۰% در کاهش توهم را بررسی میکند؛ عواملی که GPT-5.2 را به قابلاعتمادترین و توانمندترین دستیار برای محققان، مهندسان و تحلیلگران در دنیای امروز تبدیل میکند.
فهرست مطالب
- عملکرد رکوردشکن GPT 5.2: از وظایف دانشمحور تا مهندسی نرمافزار
- برتری در وظایف دانشمحور (Knowledge Work) و GDPval: مدل Thinking در مقابل متخصصان انسانی
- رکوردشکنی در SWE-Bench Pro: عملکرد عاملمحور (Agentic) و توسعه فرانتاند با GPT-5.2 Thinking
- کاهش توهم (Hallucination) به میزان ۳۰٪: افزایش صحت و قابلیت اطمینان GPT 5.2
- استدلال در محتواهای طولانی (Long Context) تا ۲۵۶ هزار توکن: تحلیل عمیق اسناد و معیار MRCRv2
- Vision پیشرفته: بهبود درک نمودارها، داشبوردها و رابطهای نرمافزاری (UI) با GPT-5.2
- برتری در فراخوانی ابزار خودکار (Agentic Tool-Calling) و مدیریت گردش کارهای End-to-End
- شتابدهی به تحقیقات علمی: نتایج GPT-5.2 در بنچمارکهای تخصصی GPQA و FrontierMath
- معیار ARC-AGI و هوش عمومی (General Reasoning): برتری در استدلال سیال
- معرفی نسخههای GPT-5.2 در ChatGPT: مدلهای Instant، Thinking و Pro برای کاربریهای مختلف
- ایمنی و امنیت GPT 5.2: استراتژی تکمیل امن (Safe Completion) و کاهش خطرات محتوایی
- موجودی و قیمتگذاری API مدل GPT-5.2: تحلیل هزینه-کارایی توکنها و دسترسی به API
- شرکای شرکت OpenAI
- جمع بندی
- سوالات متداول
شرکت OpenAI، در راستای توسعهی توانمندیهای هوش مصنوعی، اقدام به معرفی مدل جدید OpenAI با نام GPT 5.2 نموده است. این سری مدل، که تواناترین سری تاکنون به شمار میرود، بهطور ویژه برای انجام امور حرفهای و وظایف دانشمحور (knowledge-based tasks) طراحی شده است. گزارشها حاکی از آن است که در حال حاضر، کاربران نسخهی سازمانی (Enterprise) محصولات هوش مصنوعی، بهطور میانگین روزانه بین ۴۰ تا ۶۰ دقیقه در زمان خود صرفهجویی میکنند و کاربران حرفهای، این میزان صرفهجویی را به بیش از ۱۰ ساعت در هفته ارتقا دادهاند. مدل GPT-5.2 با هدف افزایش ارزش اقتصادی و بهرهوری برای کاربران، طراحی گشته و قابلیتهای خود را در حوزههای متعددی از جمله مدلسازی صفحات گسترده (spreadsheet modeling)، ساخت ارائههای جامع، مهندسی نرمافزار و کدنویسی، تحلیل بصری (درک تصاویر)، استدلال در محتواهای طولانی (Long Context Reasoning) و مدیریت پروژههای پیچیده و چندمرحلهای بهبود بخشیده است، که نشاندهنده گامی بلند در جهت هوش مصنوعی عاملی (Agentic AI) میباشد.
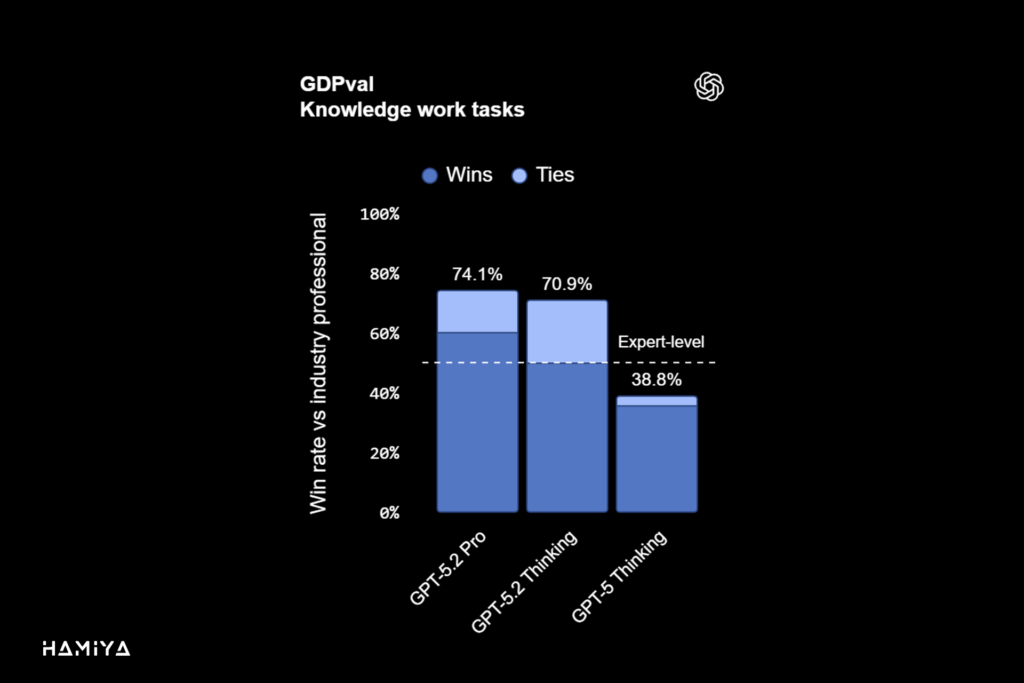
مدل GPT 5.2 موفق به ثبت یک رکورد جدید در بسیاری از معیارهای ارزیابی عملکرد شده است. از جمله این معیارها میتوان به شاخص GDPval اشاره کرد که عملکرد هوش مصنوعی را در بیش از ۴۴ حوزهی شغلی و مجموعهای از وظایف دانشمحور و دقیق تعریفشده، ارزیابی مینماید. نتایج کسبشده توسط این مدل در این معیارها، بهطور قابل توجهی از عملکرد متخصصان و کارشناسان شاغل در صنعت پیشی گرفته است، که نشاندهندهی قابلیت بیسابقهی آن در اتوماسیون کار حرفهای است.
گزارشهای متعددی از سوی شرکای تجاری کلیدی، از جمله Notion، Box، Shopify، Harvey و Zoom، عملکرد پیشرفتهی GPT-5.2 را در حوزهی استدلال در بستر طولانی (Long Context Reasoning) و قابلیت فراخوانی ابزار خودکار (automatic tool-calling) تأیید نمودهاند. علاوه بر این، شرکتهایی نظیر Databricks، Hex و Triple Whale، شاهد عملکردی استثنایی از این مدل در انجام خودکار وظایف علم داده (agentic data science) و تحلیل جامع اسناد بودهاند. همچنین، در زمینهی مهندسی نرمافزار و کدنویسی، شرکای متخصص مانند Cognition، Warp، Charlie Labs، JetBrains و Augment Code اعلام کردهاند که GPT 5.2 پیشرفتهترین سطح از کدنویسی عاملی (agentic coding) را ارائه میدهد. این بهبودهای قابل اندازهگیری شامل حوزههایی چون کدنویسی تعاملی، بازبینی کیفی کد و عیبیابی (یافتن باگها) است که بهطور کلی، توانمندیهای مدل را در نقش یک هوش مصنوعی عاملگرا تقویت مینماید.

عرضهی مدلهای جدید GPT-5.2 Instant، GPT-5.2 Thinking و GPT-5.2 Pro در بستر ChatGPT، از 11 دسامبر 2025 آغاز خواهد شده است. این عرضه در فاز نخست، برای کاربران دارای اشتراکهای پولی (paid plans) در دسترس قرار میگیرد. شایان ذکر است که این مدلها در رابط برنامهنویسی کاربردی (API)، هماکنون برای استفادهی عموم توسعهدهندگان فراهم شدهاند.
بهطور خلاصه، مدل GPT 5.2 مجموعهای از پیشرفتهای چشمگیر را در هوش عمومی، درک زمینه و محتواهای طولانی، توانمندی فراخوانی ابزار خودکار و حوزهی بینایی (vision) ارائه میدهد. تلفیق قابلیتهای بصری و متنی، آن را در قلمرو هوش مصنوعی چندوجهی (Multimodal AI) قرار میدهد. این پیشرفتها موجب شدهاند که GPT-5.2 در اجرای کامل (end-to-end) و موفقیتآمیز وظایف دانشمحور و پروژههای پیچیدهی دنیای واقعی، از تمامی مدلهای پیشین خود پیشی بگیرد و موقعیت خود را به عنوان یک هوش مصنوعی عاملی پیشرو تثبیت نماید.
عملکرد رکوردشکن GPT 5.2: از وظایف دانشمحور تا مهندسی نرمافزار
برتری در وظایف دانشمحور (Knowledge Work) و GDPval: مدل Thinking در مقابل متخصصان انسانی
GPT 5.2 Thinking به عنوان برترین مدل جدید OpenAI برای کاربردهای حرفهای و دنیای واقعی معرفی شده است. این مدل، در معیار ارزیابی GDPval، که برای سنجش عملکرد در وظایف دانشمحور (knowledge work tasks) با تعریف دقیق در ۴۴ حوزه شغلی مختلف به کار میرود، توانسته است رکورد جدیدی را ثبت کند. GPT-5.2 Thinking نخستین مدل در سری محصولات این شرکت است که عملکردی در سطح متخصصان انسانی یا حتی بالاتر از آن ارائه میدهد. بهطور مشخص، ارزیابیهای صورتگرفته توسط داوران خبره انسانی نشان میدهد که GPT 5.2 Thinking در ۷۰.۹ درصد از مقایسههای مرتبط با وظایف دانشمحور معیار GDPval، عملکردی بهتر یا برابر با متخصصان برتر صنعت داشته است. این وظایف شامل ساخت اسناد پیچیده مانند ارائهها (پرزنتیشنها) و صفحات گسترده (Spreadsheets) میباشد. همچنین، مدل Thinking خروجیهای مربوط به وظایف GDPval را با سرعتی بیش از ۱۱ برابر و با هزینهای کمتر از ۱٪ متخصصان تولید مینماید، که این امر پتانسیل بالای آن را در اتوماسیون کار حرفهای در صورت نظارت انسانی برجسته میسازد. (تخمینهای مربوط به سرعت و هزینه بر اساس معیارهای تاریخی شرکت است و سرعت در محیط ChatGPT ممکن است متغیر باشد.)
این وظایف، نیازمند تولید محصولات کاری واقعی مانند ارائه فروش، صفحات گسترده حسابداری، برنامههای زمانی مراقبتهای اورژانسی، نمودارهای تولید یا ویدیوهای کوتاه هستند.
هنگام بررسی یکی از خروجیهایی که از نظر کیفی در سطح بسیار بالایی قرار داشت، یکی از داوران خبرهی GDPval، نظر خود را به این صورت ابراز داشت:
“این کیفیت خروجی، یک جهش مهیج و قابل توجه را نشان میدهد… [به نظر میرسد] این کار توسط یک تیم حرفهای از کارشناسان انجام شده است و طرحبندی و مشاورهی ارائه شده در هر دو خروجی، بسیار عالی است؛ هرچند که هنوز برای تکمیل نهایی، نیاز به اصلاح برخی خطاهای جزئی در یکی از خروجیها وجود دارد.”
داوران خبره GDPval
این نظر، تأکید ویژهای بر توانمندی مدل Thinking در تولید نتایج حرفهای دارد و آن را بهعنوان یک هوش مصنوعی عاملی (Agentic AI) مؤثر معرفی میکند.
علاوه بر این، در معیار داخلی شرکت برای ارزیابی مدلسازی صفحات گسترده (Spreadsheet modeling) که با تمرکز بر وظایف تحلیلگران جوان بانکداری سرمایهگذاری طراحی شده است، مانند ایجاد یک مدل سهبیانیهای (three-statement model) برای یک شرکت بزرگ با قالببندی و استنادات مناسب، یا ساخت یک مدل تملیک اهرمی (leveraged buyout model) برای خصوصیسازی یک شرکت، مشاهده شد که متوسط امتیاز GPT-5.2 Thinking به ازای هر وظیفه، ۹.۳٪ بالاتر از مدل پیشین یعنی GPT-5.1 است. این امتیاز از ۵۹.۱٪ به ۶۸.۴٪ افزایش یافته است که نمایانگر بهبود قابل ملاحظهی مدل در تحلیل مالی پیشرفته میباشد.
مقایسههای مستقیم (Side-by-side comparisons) بین خروجیها، به وضوح پیچیدگی و سطح قالببندی بهبود یافته در صفحات گسترده و اسلایدهای ساخته شده توسط GPT 5.2 Thinking را نشان میدهد. این ویژگیها، به ویژه برای وظایف دانشمحور که نیازمند دقت و ارائه حرفهای هستند، بسیار حیاتی است.
برای استفاده از قابلیتهای پیشرفتهی تولید صفحات گسترده و ارائهها در محیط ChatGPT، کاربران میبایست از طرحهای (Plan) پولی Plus، Pro، Business یا Enterprise برخوردار باشند و یکی از مدلهای GPT-5.2 Thinking یا GPT 5.2 Pro را انتخاب نمایند. به دلیل ماهیت پیچیده و پردازشی بالای این وظایف دانشمحور، تولید خروجیهای نهایی ممکن است چندین دقیقه به طول بیانجامد.
رکوردشکنی در SWE-Bench Pro: عملکرد عاملمحور (Agentic) و توسعه فرانتاند با GPT-5.2 Thinking
GPT 5.2 Thinking، که بخشی از خانوادهی مدل جدید OpenAI است، با ثبت رکورد جدیدی معادل ۵۵.۶٪ در معیار SWE-Bench Pro، توانمندی خود را در مهندسی نرمافزار در محیط واقعی اثبات مینماید. معیار SWE-Bench Pro یک ابزار ارزیابی دقیق است که برخلاف معیار قبلی SWE-bench Verified که تنها زبان برنامهنویسی پایتون را میآزماید، چهار زبان برنامهنویسی مختلف را در سنجشهای خود پوشش میدهد. هدف اصلی این معیار، ایجاد یک ارزیابی مقاومتر در برابر آلودگی داده (contamination-resistant)، چالشبرانگیزتر، متنوعتر و دارای ارتباط صنعتی عمیقتر با نیازهای جاری مهندسی نرمافزار است. این موفقیت، تأییدی بر قابلیتهای پیشرفتهی هوش مصنوعی عاملی (Agentic AI) در حل مسائل پیچیدهی کدنویسی میباشد.
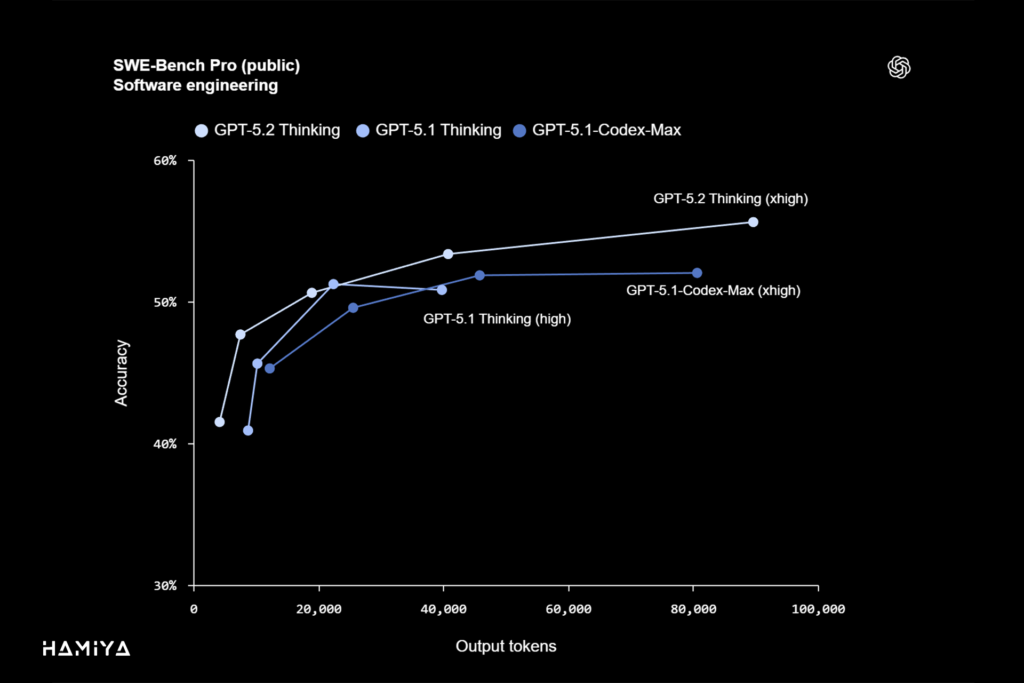
در معیار SWE-bench Verified (که در این بخش از مقاله جزئیات آماری آن ارائه نشده است)، GPT-5.2 Thinking به رکورد جدیدی برای شرکت OpenAI دست یافته که معادل ۸۰٪ میباشد. این دستاورد نشاندهندهی برتری فنی این مدل در حوزهی حل خودکار اشکالات و پیادهسازی ویژگیهای جدید است.
این عملکرد برتر به این معناست که در کاربردهای حرفهای روزمره، GPT 5.2 Thinking به مدلی تبدیل میشود که با اطمینان بیشتری میتواند کدهای تولیدی (production code) را اشکالزدایی (debug) نماید، درخواستهای مرتبط با ویژگیهای جدید (feature requests) را پیادهسازی کند، پایگاههای کد بزرگ (large codebases) را بازسازی (refactor) نماید و اصلاحات (fixes) را بهصورت کامل (end-to-end) و با حداقل مداخلهی دستی به انجام برساند. این ویژگیها، مدل را به یک ابزار برجسته در اتوماسیون کار حرفهای برای توسعهدهندگان تبدیل میکند.
علاوه بر این، GPT-5.2 Thinking در حوزهی توسعه فرانتاند (front-end development) و مهندسی نرمافزار، نسبت به مدل پیشین خود، GPT-5.1 Thinking، پیشرفت چشمگیری از خود نشان میدهد. آزمایشکنندگان اولیه گزارش دادهاند که این مدل بهطور قابل توجهی در توسعه فرانتاند و انجام وظایف پیچیده یا غیرمتعارف رابط کاربری (UI)، به ویژه در مواردی که شامل عناصر سهبعدی میشوند، قدرتمندتر عمل میکند. این قابلیتها، آن را به یک شریک روزمره و توانمند برای مهندسان در تمامی لایههای پشته فناوری (full stack) تبدیل میسازد.
کاهش توهم (Hallucination) به میزان ۳۰٪: افزایش صحت و قابلیت اطمینان GPT 5.2
یکی از پیشرفتهای چشمگیر در مدل جدید OpenAI، یعنی GPT-5.2 Thinking، کاهش قابل توجه میزان توهم وش مصنوعی (Hallucination) نسبت به مدل قبلی، GPT-5.1 Thinking، است. توهم به تولید اطلاعات نادرست یا ساختگی توسط مدلهای هوش مصنوعی گفته میشود. در یک مجموعه دادهی متشکل از جستجوهای غیرقابل شناسایی (de-identified) کاربران ChatGPT، پاسخهایی که شامل خطا بودند، به میزان ۳۰٪ نسبی کاهش توهم را نشان دادهاند. این امر به صورت مستقیم به افزایش قابلیت اطمینان مدل منجر شده و به متخصصان این امکان را میدهد تا با اطمینان بیشتری از مدل برای انجام فعالیتهای حیاتی مانند پژوهش، نگارش، تحلیل داده و حمایت از تصمیمگیری استفاده نمایند. بنابراین، برای اجرای وظایف دانشمحور روزمره، این مدل بهعنوان یک هوش مصنوعی عاملگرا (Agentic AI)، قابل اعتمادتر ارزیابی میگردد.
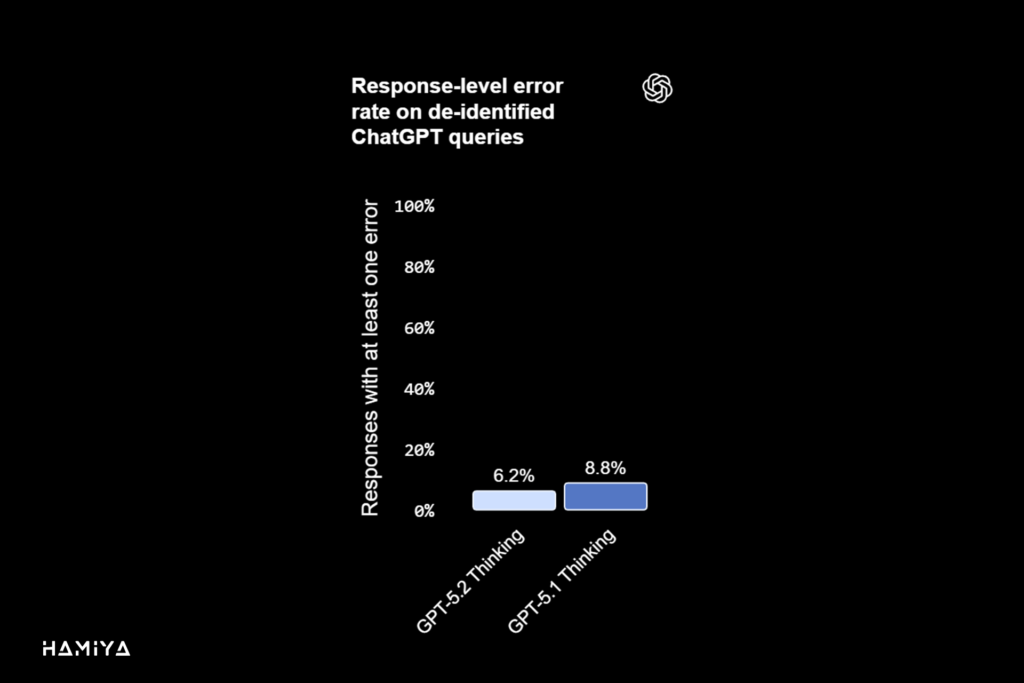
خطاها توسط مدلهای دیگری تشخیص داده شدند که ممکن است خودشان نیز مرتکب خطا شوند. نرخ خطای در سطح ادعا (Claim-level error rates) بسیار پایینتر از نرخ خطای در سطح پاسخ (response-level error rates) است، زیرا اکثر پاسخها حاوی ادعاهای متعددی هستند.
با وجود پیشرفتهای حاصلشده در زمینهی کاهش توهم، لازم به ذکر است که GPT 5.2 Thinking مانند سایر مدلهای زبانی بزرگ، همچنان کامل و بینقص نیست. از این رو، اکیداً توصیه میشود که برای هر گونه اطلاعات یا خروجی که جنبهی حیاتی یا حساس دارد، پاسخهای ارائه شده توسط مدل مجدداً توسط کاربر بررسی و تأیید شوند تا از صحت و دقت نهایی اطمینان حاصل گردد.
استدلال در محتواهای طولانی (Long Context) تا ۲۵۶ هزار توکن: تحلیل عمیق اسناد و معیار MRCRv2
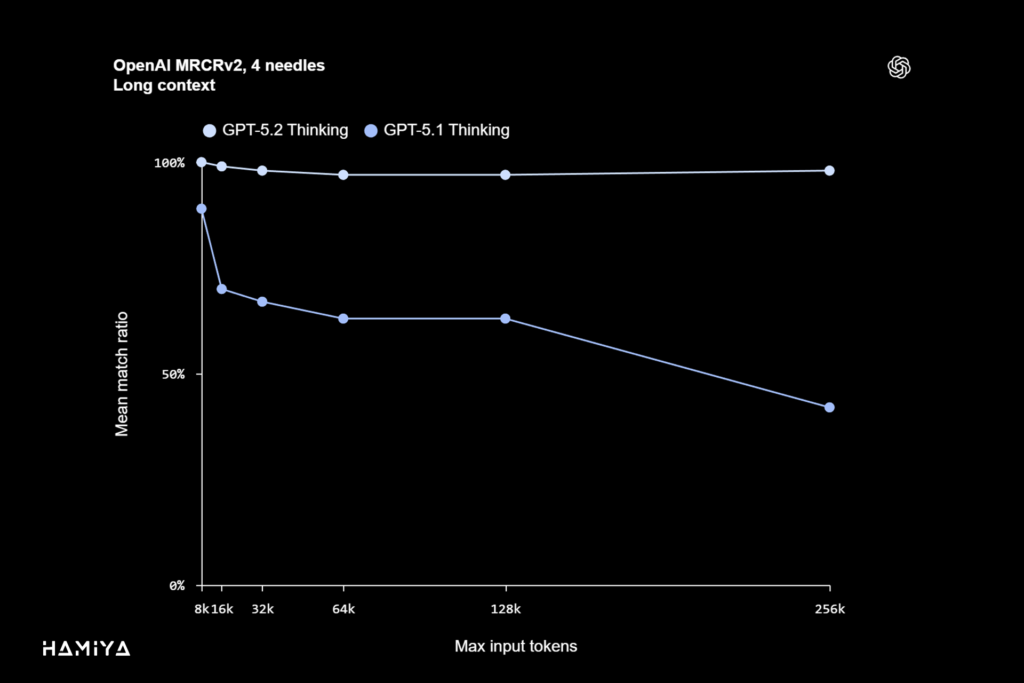
GPT-5.2 Thinking یک رکورد جدید در قابلیت استدلال در محتواهای طولانی (Long Context Reasoning) ثبت نموده و به عملکرد پیشرو در معیار داخلی OpenAI به نام MRCRv2 دست یافته است. معیار MRCRv2 بهطور خاص، توانایی مدل را در یکپارچهسازی و استخراج اطلاعاتی میسنجد که در میان اسناد بسیار طولانی بهصورت پراکنده وجود دارند. در وظایف دانشمحور دنیای واقعی، نظیر تحلیل عمیق اسناد (deep document analysis) که نیازمند دسترسی به دادههای مرتبط در میان صدها هزار توکن هستند، GPT 5.2 Thinking بهطور قابل ملاحظهای دقیقتر از مدل قبلی، GPT-5.1 Thinking، عمل مینماید. نکتهی حائز اهمیت آن است که این مدل، اولین نمونهای است که شرکت OpenAI مشاهده کرده و توانسته است تقریباً به دقت ۱۰۰٪ در نوع ۴-سوزنه (4-needle) معیار MRCR (تا سقف ۲۵۶ هزار توکن) دست پیدا کند.اگر نمیدانید که مفاهیم توکن، Context Window یا همان پنجره زمینه (که در برخی منابع به پنجره زمینه نیز شناخته میشود) به چه معنا هستند، توصیه میشود مقاله جامع و تخصصی “رمزگشایی از دنیای هوش مصنوعی و LLM: از توکنها تا پنجرههای کانالی” از هامیا ژورنال را مطالعه نمائید.
از منظر کاربردی، این افزایش چشمگیر در زمینه و محتوا (context) و قابلیت استدلال در محتوای طولانی، متخصصان را قادر میسازد تا از GPT 5.2 بهعنوان یک هوش مصنوعی عاملی (Agentic AI) برای پردازش و کار با اسناد بسیار حجیم، مانند گزارشهای جامع، قراردادهای پیچیده، مقالات تحقیقاتی، رونوشتهای طولانی و پروژههای چندفایلی، استفاده کنند. این مدل توانایی خود را در حفظ انسجام و دقت بالا در میان صدها هزار توکن اطلاعاتی اثبات میکند. بنابراین، این ویژگی GPT-5.2 Thinking را بهویژه برای انجام تحلیل عمیق اسناد، ترکیب اطلاعات (synthesis) و اجرای گردشهای کاری پیچیده با منابع متعدد، بسیار مناسب میسازد.
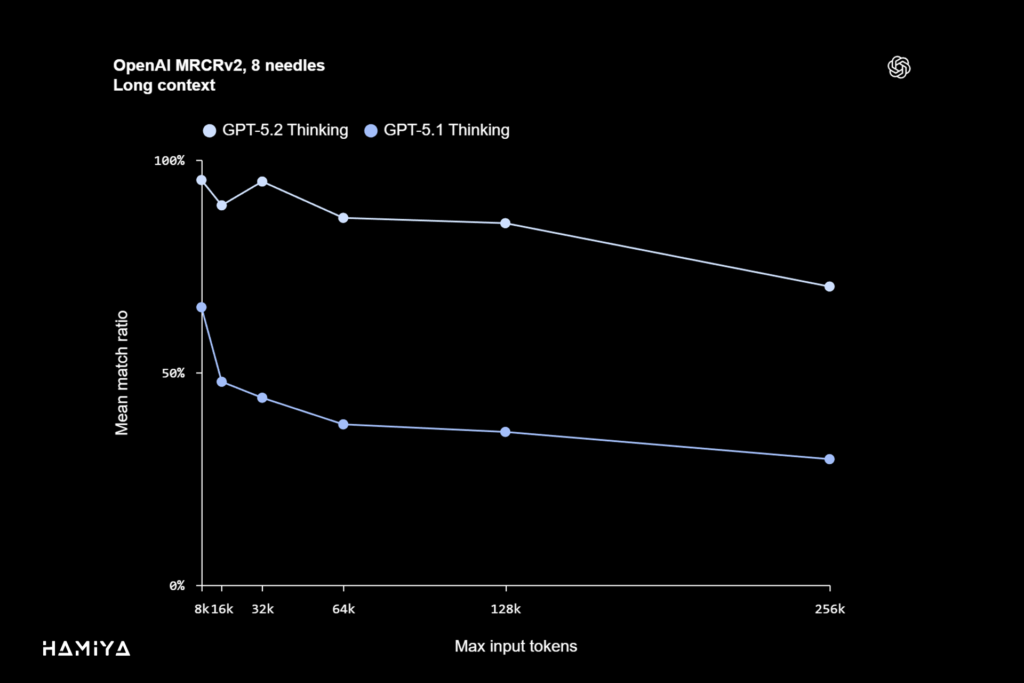
برای آن دسته از وظایف دانشمحور که نیازمند فرایند تفکر فراتر از پنجره کانالی (maximum context window) استاندارد مدل هستند، GPT 5.2 Thinking با نقطهی پایانی (endpoint) جدید Responses /compact شرکت OpenAI سازگار است. این قابلیت جدید، پنجرهی بستر مؤثر مدل را بهطور استراتژیک گسترش میدهد. با بهرهگیری از این ویژگی، GPT-5.2 Thinking میتواند بهصورت موفقیتآمیزی از عهدهی جریانهای کاری طولانیمدت و نیازمند فراخوانی ابزار خودکار (automatic tool-calling) برآید؛ فرآیندهایی که در مدلهای قبلی به دلیل محدودیتهای طول بستر، قابل اجرا نبودند.
Vision پیشرفته: بهبود درک نمودارها، داشبوردها و رابطهای نرمافزاری (UI) با GPT-5.2
GPT 5.2 Thinking به عنوان قویترین مدل بینایی (vision) شرکت OpenAI تا به امروز معرفی شده است. این مدل توانسته است نرخ خطاهای مربوط به درک نمودار (chart reasoning) و فهم رابط نرمافزاری (software interface understanding) را تقریباً به نصف کاهش دهد. این پیشرفتها، مدل را به یک ابزار هوش مصنوعی چندوجهی (Multimodal AI) کارآمد تبدیل میکند که میتواند دادههای بصری را با دقت بیسابقهای تحلیل و تفسیر نماید.
در کاربردهای حرفهای و روزمره، این عملکرد بهتر در حوزهی Vision پیشرفته به این معناست که GPT-5.2 Thinking میتواند داشبوردهای تحلیلی، تصاویر صفحهی محصول (product screenshots)، نمودارهای فنی پیچیده و گزارشهای بصری را با صحت بالاتری تفسیر کند. این قابلیت، به مدل امکان میدهد تا بهطور مؤثری از گردشهای کاری در حوزههای مالی، عملیات، مهندسی نرمافزار، طراحی و پشتیبانی مشتری که اطلاعات بصری نقش محوری در آنها دارند، حمایت نماید و گامی دیگر در اتوماسیون کار حرفهای بردارد.
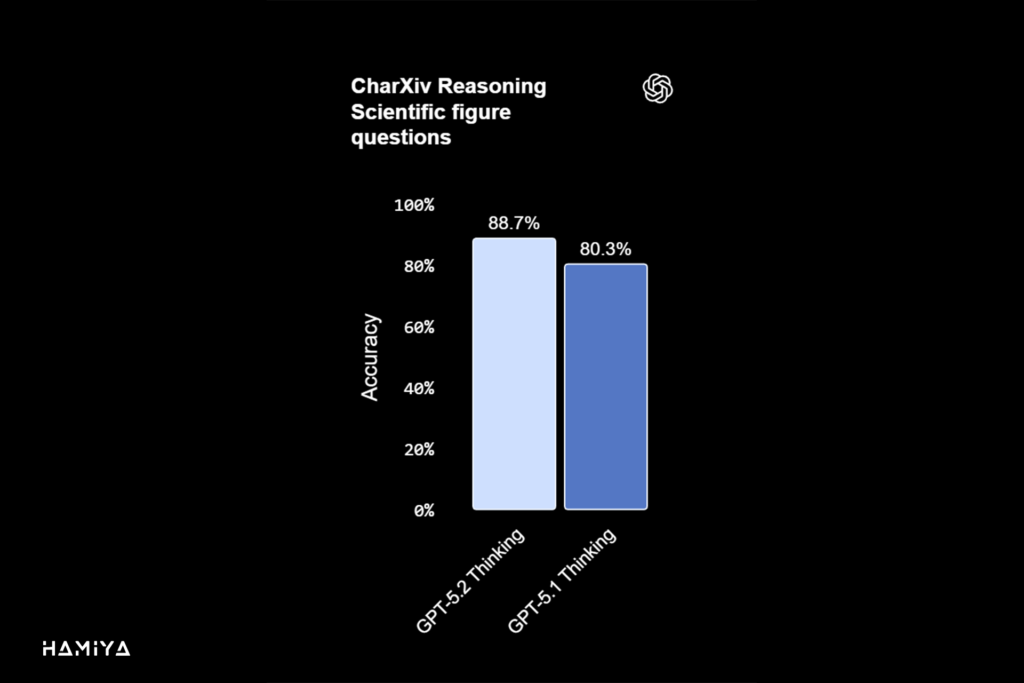
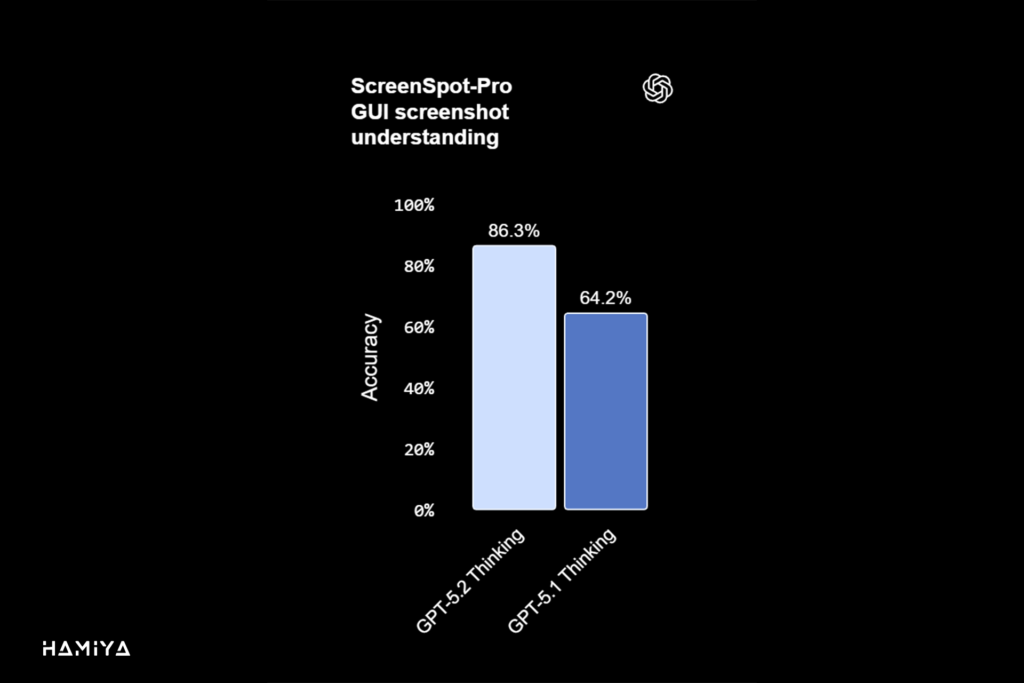
در این ارزیابی، یک ابزار پایتون (Python tool) فعال شده بود و تلاش استدلال (reasoning effort) روی حداکثر میزان تنظیم شده بود. بدون ابزار پایتون، امتیازات بسیار پایینتر هستند. توصیه میکنیم که ابزار پایتون را برای وظایف بینایی (vision tasks) شبیه به این موارد فعال کنید.
در مقایسه با نسلهای قبلی، GPT 5.2 Thinking از درک قویتری نسبت به چگونگی موقعیتیابی عناصر در یک تصویر برخوردار است. این ویژگی بهطور خاص در وظایف دانشمحوری که در آنها آرایش نسبی عناصر، کلید حل مسئله است، بسیار یاریرسان خواهد بود. برای مثال، در یک نمونه که از مدل خواسته میشود اجزای یک ورودی تصویری (مانند یک مادربرد کامپیوتر) را شناسایی کند و برچسبهایی همراه با کادرهای مرزی تقریبی (approximate bounding boxes) بازگرداند، مشاهده شده است: حتی در یک تصویر با کیفیت پایین، GPT-5.2 Thinking توانسته است نواحی اصلی را تشخیص دهد و کادرهایی را منطبق با مکانهای واقعی هر جزء قرار دهد. این در حالی است که GPT-5.1 تنها قادر به برچسبگذاری بخشهای محدودی بوده و درک بسیار ضعیفتری از آرایش فضایی آنها ارائه داده است. اگرچه هر دو مدل ممکن است اشتباهات جزئی داشته باشند، اما GPT 5.2 سطح درک بسیار بهتری از محتوای تصویر نشان میدهد که برتری آن را در پردازش زبان طبیعی پیشرفته (NLP) و تلفیق آن با بینایی ثابت میکند.
برتری در فراخوانی ابزار خودکار (Agentic Tool-Calling) و مدیریت گردش کارهای End-to-End
GPT-5.2 Thinking یک رکورد جدید با امتیاز ۹۸.۷٪ در معیار Tau2-bench Telecom ثبت نموده است. این معیار، توانایی مدل را در استفادهی قابل اعتماد از ابزارهای مختلف در طول اجرای وظایف دانشمحور و چند مرحلهای (multi-turn tasks) به نمایش میگذارد. این دستاورد، برتری مدل در قابلیت فراخوانی ابزار خودکار (automatic tool-calling) را تأیید میکند و نشاندهندهی یک پیشرفت مهم در راستای تکامل آن به سمت یک هوش مصنوعی عاملگرا (Agentic AI) پیشرفته میباشد.
برای کاربردهایی که به تأخیر کم (latency-sensitive use cases) اهمیت زیادی میدهند، GPT 5.2 Thinking حتی در حالتی که سطح تلاش برای استدلال (reasoning.effort=’none’) روی حداقل تنظیم شده است، همچنان عملکرد به مراتب بهتری در استدلال از خود نشان میدهد. این عملکرد نیز بهطور قابل ملاحظهای از مدلهای پیشین یعنی GPT-5.1 و GPT-4.1 سبقت میگیرد و امکان اتوماسیون کار حرفهای سریع و دقیق را فراهم میآورد.
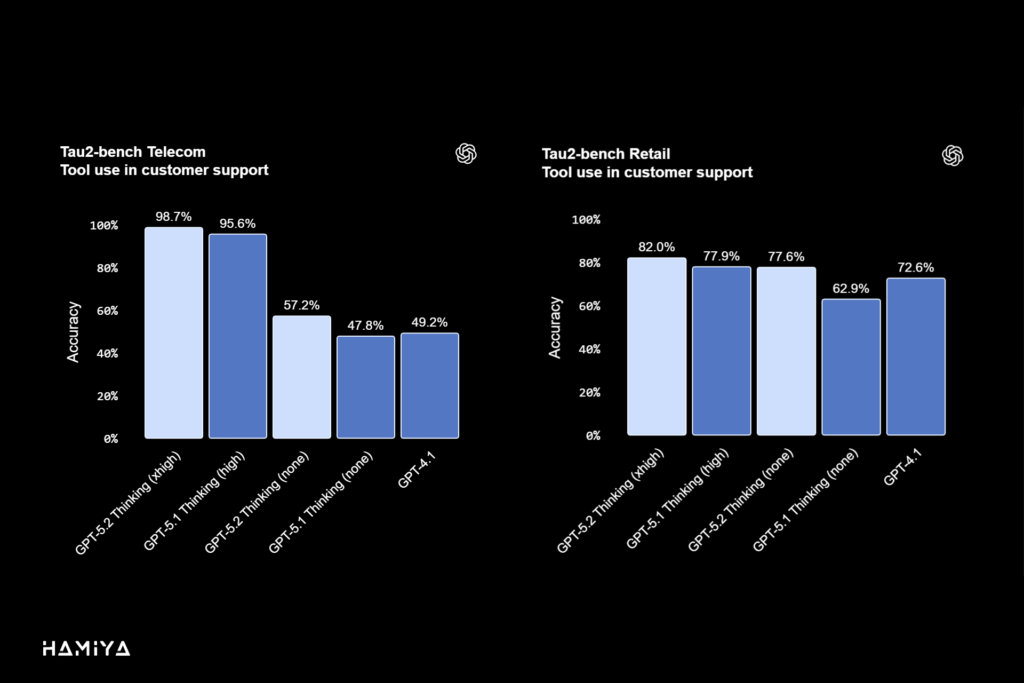
برای دامنه مخابرات (Telecom)، ما یک دستورالعمل مختصر و به طور کلی مفید را در فرمان سیستمی (system prompt) قرار دادیم تا عملکرد مدل افزایش یابد. ما زیرمجموعه خطوط هوایی (Airline subset) را به دلیل کیفیت پایینتر در درجهبندی پاسخ صحیح (ground truth grading) حذف کردیم.
برای متخصصان، این عملکرد بهبود یافته به توسعهی گردش کار End-to-End (End-to-End Workflows) قویتر و کاملتری منجر میشود. این گردشهای کاری شامل فعالیتهایی نظیر حل خودکار پروندههای پیچیدهی پشتیبانی مشتری، استخراج دادهها از چندین سیستم اطلاعاتی، اجرای تحلیلهای پیشرفته و تولید خروجیهای نهایی با کاهش وقفه (breakdowns) و نیاز به مداخلهی انسانی بین مراحل است.
بهعنوان یک مثال عینی، هنگام رسیدگی به یک سؤال پیچیدهی خدمات مشتری که مستلزم حل چند مرحلهای است، مدل میتواند بهطور مؤثرتری کل گردش کار End-to-End را در میان چندین عامل (agents) هماهنگ کند. در سناریوی زیر، فرض کنید یک مسافر نیاز به کمک در مورد تأخیر پرواز، از دست دادن پرواز اتصال (missed connection)، یک شب اقامت اضطراری و نیاز به صندلی مخصوص به دلایل پزشکی را گزارش میدهد. GPT-5.2 Thinking کل زنجیرهی وظایف را شامل رزرو مجدد (rebooking)، تخصیص صندلی کمک ویژه و انجام مراحل جبران خسارت، با موفقیت مدیریت نموده و خروجی کاملتری نسبت به مدل GPT-5.1 ارائه میدهد. این توانایی در مدیریت سناریوهای پیچیده، برجستهترین ویژگی هوش مصنوعی عاملی در GPT 5.2 است.
شتابدهی به تحقیقات علمی: نتایج GPT-5.2 در بنچمارکهای تخصصی GPQA و FrontierMath
یکی از آرمانهای اصلی در توسعهی هوش مصنوعی عاملگرا (Agentic AI)، تسریع روند تحقیقات علمی به نفع کل جامعهی بشری است. در همین راستا، شرکت OpenAI با دانشمندان همکاریهای نزدیکی داشته و با در نظر گرفتن نیازهای آنها، نحوهی کاربرد هوش مصنوعی برای سرعت بخشیدن به کار علمی را مورد بررسی قرار داده است.
تیم هامیا که متشکل از دکترین برجسته، پژوهشگران نمونه، نخبههای علمی، فناوران صنعتی، تحلیلگران داده سطح بالا و معماران سیستمهای هوشمند میباشند، بر این باورند که مدلهای GPT-5.2 Pro و GPT-5.2 Thinking در حال حاضر، بهترین مدلهای جهان (یا حداقل جزوی از بهترینها) برای کمک و شتابدهی به فعالیتهای دانشمندان محسوب میشوند. در معیار GPQA Diamond، که یک معیار سنجش پرسش و پاسخ (Q&A) در سطح فارغالتحصیلی (graduate-level) و مبتنی بر شواهد است و توسط شرکت گوگل توسعه یافته، GPT 5.2 Pro به امتیاز ۹۳.۲٪ دست یافته است. پس از آن، GPT-5.2 Thinking با اختلاف اندکی امتیاز ۹۲.۴٪ را کسب میکند. این نتایج نشاندهندهی توانایی بینظیر مدلهای GPT 5.2 در درک و استدلال بر روی مفاهیم پیچیدهی علمی است.
علاوه بر این، در معیار FrontierMath (سطوح ۱ تا ۳)، که ارزیابی تخصصی از ریاضیات در سطح خبرگان (expert-level) است، GPT-5.2 Thinking با حل ۴۰.۳٪ از مسائل، رکورد جدیدی را ثبت نمود. این عملکرد عالی در FrontierMath نشان میدهد که این مدل، فراتر از یک ابزار سادهی پردازش زبان طبیعی پیشرفته (NLP) عمل کرده و در انجام محاسبات و استدلالهای ریاضی پیچیده در سطح تحقیقات علمی نیز کارآمد است.
در حال حاضر، شاهد آن هستیم که مدلهای پیشرفتهی هوش مصنوعی، مانند GPT 5.2 Pro، پیشرفت در حوزههای ریاضیات و علوم را بهطور ملموسی و معنادار سرعت میبخشند. بهعنوان مثال، در جریان کار اخیر با GPT-5.2 Pro، محققان یک سوال حلنشده در زمینهی نظریهی یادگیری آماری (statistical learning theory) را مورد بررسی قرار دادند. در یک محیط محدود و کاملاً مشخص، این مدل موفق به ارائهی یک اثبات (proof) شد که متعاقباً توسط نویسندگان تأیید و با متخصصان بیرونی نیز بررسی گردید. این مورد، بهوضوح نشان میدهد که چگونه مدلهای پیشرو میتوانند تحت نظارت دقیق انسان، به پیشبرد تحقیقات علمی و ریاضیاتی کمک شایانی نمایند.
معیار ARC-AGI و هوش عمومی (General Reasoning): برتری در استدلال سیال
در معیار ARC-AGI-1 (تأیید شده)، که بهطور خاص برای سنجش قابلیت استدلال عمومی (General Reasoning) طراحی شده است، GPT 5.2 Pro به عنوان اولین مدل موفق به عبور از آستانهی ۹۰٪ شده است. این عملکرد، در مقایسه با نسخهی پیشنمایش o3 که سال گذشته امتیاز ۸۷٪ را کسب کرده بود، بهبود یافته است. نکتهی مهمتر آنکه، این پیشرفت با کاهش تقریباً ۳۹۰ برابری در هزینهی دستیابی به این سطح عملکرد همراه بوده است. این دستاورد، نشاندهندهی کارایی و پتانسیل بالای این مدل به عنوان یک سیستم در مسیر دستیابی به هوش عمومی مصنوعی (AGI) میباشد.
همچنین در معیار ARC-AGI-2 (تأیید شده)، که سطح دشواری را افزایش داده و بهطور مؤثرتری قابلیت استدلال سیال (fluid reasoning) را تفکیک میکند، GPT 5.2 Thinking با کسب امتیاز ۵۲.۹٪، یک رکورد جدید را برای مدلهای مبتنی بر زنجیرهی تفکر (chain-of-thought) به ثبت میرساند. مدل قدرتمندتر GPT-5.2 Pro حتی عملکرد بالاتری داشته و به ۵۴.۲٪ میرسد. این نتایج حاکی از آن است که توانایی مدل جدید OpenAI برای انجام استدلال در مسائل جدید، انتزاعی و پیچیده، به میزان قابل توجهی گسترش یافته است.
بهبودهایی که در سرتاسر این ارزیابیهای معتبر مشاهده میشود، منعکسکنندهی قدرت بیشتر GPT 5.2 در استدلال چندمرحلهای، دقت کمی بالاتر و حل مسئلهی قابل اعتمادتر در وظایف دانشمحور و فنی پیچیده است. این ویژگیها، مدل را به یک هوش مصنوعی عاملی (Agentic AI) مؤثرتر برای کاربردهای مهندسی نرمافزار و تحلیل تبدیل میکند.
معرفی نسخههای GPT-5.2 در ChatGPT: مدلهای Instant، Thinking و Pro برای کاربریهای مختلف
در پلتفرم ChatGPT، کاربران هنگام استفادهی روزمره متوجه تجربهی کاربری بسیار بهتری خواهند شد. این تجربه جدید با سری مدلهای GPT 5.2، ساختارمندتر، قابل اعتمادتر و همچنان لذتبخش برای تعاملات مکالمهای طراحی شده است.
GPT-5.2 Instant یک مدل جدید OpenAI است که با هدف ارائهی سرعت بالا و توانایی کافی برای کار و یادگیری روزمره توسعه یافته است. این نسخه، بهبودهای واضحی را در پاسخدهی به پرسشهای جستجوی اطلاعات، ارائهی راهنماها و آموزشها (how-tos and walk-throughs)، نگارش فنی و ترجمه نشان میدهد. این پیشرفتها بر اساس لحن گرم و مکالمهای مدل GPT-5.1 Instant بنا شدهاند. آزمایشکنندگان اولیه به این نکته اشاره کردهاند که توضیحات ارائه شده توسط GPT 5.2 Instant بسیار واضحتر هستند و اطلاعات کلیدی را در ابتدای پاسخها برجسته میکنند.
GPT-5.2 Thinking بهطور ویژه برای وظایف دانشمحور عمیقتر طراحی شده است و به کاربران کمک میکند تا با دقت بیشتری به حل مسائل پیچیدهتر بپردازند. کاربردهای کلیدی این مدل شامل مهندسی نرمافزار و کدنویسی پیشرفته، خلاصهسازی اسناد دارای استدلال در محتواهای طولانی (Long Context Reasoning)، پاسخ به سؤالات بر اساس فایلهای آپلودشده، حل گام به گام مسائل ریاضی و منطقی و همچنین پشتیبانی از برنامهریزی و تصمیمگیری با ارائهی ساختار واضحتر و جزئیات مفیدتر میباشد. این مدل، تجسمی از پیشرفت در مسیر هوش مصنوعی عاملی (Agentic AI) برای تحلیل دادهها است.
GPT 5.2 Pro هوشمندترین و قابل اعتمادترین گزینهی شرکت OpenAI برای رسیدگی به پرسشهای بسیار دشوار است؛ یعنی مواردی که ارزش یک پاسخ با بالاترین کیفیت، توجیه کنندهی انتظار برای تکمیل پردازش باشد. این مدل در حوزههای فنی پیچیدهای مانند برنامهنویسی و مهندسی نرمافزار، عملکردی قویتر از خود نشان میدهد و آزمایشهای اولیه، کاهش چشمگیر اشتباهات عمده را در این نسخه اثبات کردهاند. GPT-5.2 Pro در واقع نهایت کارایی خانوادهی GPT-5.2 را برای وظایف دانشمحور حساس، ارائه میدهد.
ایمنی و امنیت GPT 5.2: استراتژی تکمیل امن (Safe Completion) و کاهش خطرات محتوایی
GPT-5.2 بر پایهی یافتهها و پژوهشهای مرتبط با مفهوم تکمیل امن (Safe Completion) بنا شده است که شرکت OpenAI با معرفی GPT-5 پایهریزی کرد. این استراتژی آموزشی، به مدل جدید OpenAI میآموزد که همزمان با ارائهی مفیدترین پاسخهای ممکن، بهطور پیوسته در محدودهی مرزهای ایمنی GPT 5.2 و اخلاق هوش مصنوعی باقی بماند. این رویکرد، برای توسعهی یک هوش مصنوعی عاملگرا (Agentic AI) قابل اعتماد در وظایف دانشمحور بسیار حیاتی است.
با عرضهی کنونی، کار شرکت OpenAI برای تقویت پاسخهای مدلهایشان در تعاملات حساس ادامه پیدا کرده است. این بهبودها، بهطور معناداری، در نحوهی واکنش مدل به درخواستهایی که نشاندهندهی علائم خودکشی یا آسیب به خود، پریشانی سلامت روان، یا وابستگی عاطفی به مدل هستند، دیده میشود. این مداخلات هدفمند به کاهش پاسخهای نامطلوب در مدلهای GPT 5.2 Instant و GPT 5.2 Thinking در مقایسه با نسخههای پیشین خود، یعنی GPT-5.1 و GPT-5 Instant و Thinking منجر شده است.
شرکت OpenAI در مراحل اولیهی پیادهسازی مدل پیشبینی سن کاربران قرار دارد. هدف از این اقدام، اعمال خودکار تمهیدات حفاظتی محتوایی برای کاربرانی است که زیر ۱۸ سال سن دارند، تا دسترسی آنها به محتوای حساس محدود شود. این فرآیند بر مبنای رویکرد موجود برای کاربران زیر ۱۸ سال و همچنین کنترلهای والدین (parental controls) بنا شده است و بخشی از تعهد شرکت به رعایت اصول ایمنی و اخلاق هوش مصنوعی است.
GPT-5.2 تنها یک گام در یک سری از بهبودهای مداوم در زمینهی هوش مصنوعی عاملی و اتوماسیون کار حرفهای است و این شرکت هنوز فاصلهی زیادی تا پایان مسیر توسعهی کامل دارد. در حالی که این عرضه دستاوردهای معناداری را در هوش و بهرهوری ارائه میدهد، شرکت OpenAI اذعان دارد که حوزههایی وجود دارند که کاربران خواستار بهبود بیشتری در آنها هستند. در پلتفرم ChatGPT، کارشناسان در حال رفع مشکلات شناختهشدهای مانند امتناعهای بیش از حد (over-refusals) هستند؛ در عین حال، به بالا بردن استاندارد ایمنی و امنیت هوش مصنوعی و قابلیت اطمینان مدل ادامه میدهند. از آنجا که این تغییرات دارای پیچیدگیهای فنی و اخلاقی هستند، تمرکز اصلی بر انجام صحیح و اصولی آنها است.
موجودی و قیمتگذاری API مدل GPT-5.2: تحلیل هزینه-کارایی توکنها و دسترسی به API
عرضهی مدلهای GPT 5.2 (شامل Instant، Thinking و Pro) در محیط ChatGPT از 11 دسامبر 2025 آغاز شده و در ابتدا برای کاربرانی که دارای طرحهای پولی (Plus, Pro, Go, Business, Enterprise) هستند، در دسترس قرار خواهد گرفت. شرکت OpenAI این مدل جدید OpenAI را بهصورت تدریجی عرضه میکند تا اطمینان حاصل شود که پلتفرم ChatGPT در بالاترین سطح روان بودن و قابلیت اطمینان باقی بماند؛ لذا اگر کاربران در ساعات اولیه به این مدلها دسترسی پیدا نکردند، توصیه میشود در زمان دیگری مجدداً تلاش نمایند. در محیط ChatGPT، مدل GPT-5.1 همچنان برای مدت سه ماه بهعنوان مدلهای قدیمی (legacy models) برای کاربران پولی در دسترس خواهد بود و پس از آن، ارائهی خدمات GPT-5.1 متوقف (sunset) خواهد شد.
در پلتفرم GPT-5.2 API، مدل GPT 5.2 Thinking از امروز با نام gpt-5.2 در API پاسخها (Responses API) و API تکمیل چت (Chat Completions API) قابل دسترسی است و GPT-5.2 Instant با شناسه gpt-5.2-chat-latest ارائه میگردد. همچنین، GPT 5.2 Pro با نام gpt-5.2-pro در API پاسخها موجود است. توسعهدهندگان اکنون این امکان را دارند که پارامتر استدلال (reasoning parameter) را در GPT-5.2 Pro تنظیم کنند. علاوه بر این، هر دو مدل GPT-5.2 Pro و GPT-5.2 Thinking از سطح تلاش پنجم استدلال (fifth reasoning effort) جدیدی تحت عنوان xhigh پشتیبانی میکنند، که برای وظایف دانشمحور حیاتی که در آنها کیفیت برتری مطلق دارد، طراحی شده است.
قیمت API مدل GPT 5.2 برای توکنهای ورودی ۱.۷۵ دلار به ازای هر یک میلیون توکن و برای توکنهای خروجی ۱۴ دلار به ازای هر یک میلیون توکن تعیین شده است. همچنین، ۹۰٪ تخفیف برای ورودیهایی که در حافظه نهان (cached inputs) ذخیره شدهاند، اعمال میگردد. در ارزیابیهای متعدد مبتنی بر عاملیت (agentic evals)، شرکت OpenAI به این نتیجه رسیده است که با وجود بالاتر بودن هزینه به ازای هر توکن در GPT-5.2، هزینه-کارایی توکن بالاتر این مدل در نهایت باعث میشود که دستیابی به سطح معینی از کیفیت در وظایف دانشمحور و مهندسی نرمافزار، به لحاظ اقتصادی، ارزانتر تمام شود.
در حالی که ساختار قیمتگذاری اشتراک ChatGPT بدون تغییر باقی مانده است، در API قیمت GPT 5.2 به ازای هر توکن نسبت به GPT-5.1 بالاتر است؛ دلیل این امر، قابلیت و هوشمندی بسیار بالاتر مدل در زمینهی هوش مصنوعی عاملگرا و استدلال در محتوای طولانی (Long Context Reasoning) است. با این وجود، این مدل همچنان قیمتی پایینتر از سایر مدلهای پیشرو (frontier models) در بازار دارد، تا توسعهدهندگان بتوانند از آن بهطور گسترده در کارهای روزمره و کاربردهای اصلی خود استفاده نمایند.
در حال حاضر، هیچ برنامهای برای توقف پشتیبانی (deprecate) از مدلهای GPT-5.1، GPT-5 یا GPT-4.1 در API در دستور کار شرکت OpenAI قرار ندارد و هرگونه تصمیمگیری در این خصوص، با اطلاع قبلی کافی به توسعهدهندگان اعلام خواهد شد. لازم به ذکر است که اگرچه GPT-5.2 بدون تنظیمات خاص نیز با Codex بهخوبی کار میکند، انتظار میرود که نسخهای از GPT 5.2 که بهطور ویژه برای Codex بهینهسازی شده باشد، در هفتههای آینده منتشر گردد تا عملکرد آن در کدنویسی و مهندسی نرمافزار به حداکثر برسد.
شرکای شرکت OpenAI
GPT-5.2 با همکاری شرکای دیرینه شرکت سازنده آن، NVIDIA و Microsoft ساخته شده است. مراکز داده Azure و پردازندههای گرافیکی NVIDIA، از جمله H100، H200 و GB200-NVL72، زیرساخت آموزشی در مقیاس بزرگ OpenAI را پشتیبانی میکنند و باعث افزایش قابل توجهی در هوش مدل میشوند. این همکاری در مجموع به شرکت OpenAI اجازه میدهد تا توان محاسباتی (compute) را با اطمینان مقیاسبندی کرده و مدلهای جدید را سریعتر به بازار عرضه کنند.
جمع بندی
تحلیل عمیق این مقاله از GPT 5.2 تأیید میکند که ما در آستانه جهشی بنیادین در مسیر هوش مصنوعی عاملی قرار داریم؛ مدلی که خود را نه به عنوان یک کمککننده ساده، بلکه به عنوان یک نیروی پیشران در اقتصاد مدرن معرفی کرده است. کسب رتبههای بیسابقه در بنچمارکهای سختگیرانهای چون GDPval برای وظایف مدیریتی و SWE-Bench Pro در مهندسی نرمافزار، گواه آن است که GPT-5.2 مرز عملکرد در وظایف دانشمحور را به سطح متخصصان انسانی رسانده است. این پیشرفت، صرفاً یک دستاورد فنی نیست؛ از منظر لیبرال کلاسیک، این مدل ابزاری برای اعتلای فرد و کاهش مداخلههای غیرضروری است. با کاهش ۳۰% نرخ توهم، افزایش قابلیت اطمینان، و توانایی استدلال در بستر طولانی تا ۲۵۶ هزار توکن، این فناوری قدرت آفرینش، تحلیل و اتوماسیون را در اختیار افراد قرار میدهد تا به جای درگیر شدن در فرآیندهای پرهزینه و زمانبر، تمرکز خود را بر نوآوری و خلق ارزش بگذارند.
در نهایت، مدل GPT-5.2 به متخصصان امکان میدهد تا با سرعتی بیسابقه به اهداف خود برسند و کارایی را با هزینه-کارایی توکنها مجدداً تعریف کنند. این تکامل، بازار را رقابتیتر ساخته و نوآوری را تسریع میبخشد؛ دستاوردی که در هر نظام اقتصادی پویا یک اصل اساسی محسوب میشود. ما مشاهده کردیم که GPT 5.2 در درک نمودارها از طریق Vision پیشرفته و مدیریت گردش کارهای End-to-End بینظیر عمل میکند، و اکنون وظیفه استفاده هوشمندانه و اخلاقی از این پتانسیل عظیم، بر عهده هر توسعهدهنده و سازمان پیشرو است. با در دسترس قرار گرفتن نسخههای Thinking، Instant و Pro در API و ChatGPT، این مقاله نه تنها نقشهای از قابلیتهای موجود را ترسیم میکند، بلکه چراغ راهی است برای درک نحوه استفاده از قویترین اهرمهای اقتصادی و فناورانه موجود در جهان امروز.
سوالات متداول
بله، مدل GPT-5.2 Thinking در معیار GDPval، که وظایف دانشمحور در ۴۴ شغل را اندازهگیری میکند، عملکردی برابر یا بهتر از متخصصان برتر صنعت در ۷۰.۹% مقایسهها نشان داده است. این مدل به طور خاص در تولید خروجیهای مربوط به ساخت صفحات گسترده و ارائهها، برتری قابل توجهی دارد.
GPT 5.2 Thinking با ثبت رکورد جدید ۵۵.۶% در SWE-Bench Pro، پیشرفتهترین عملکرد کدنویسی عاملگرا (Agentic Coding) را ارائه میدهد. این مدل بهطور قابل ملاحظهای در اشکالزدایی (Debug) کدهای تولیدی، بازسازی پایگاههای کد بزرگ، و توسعه فرانتاند بهتر عمل میکند.
GPT-5.2 Thinking در زمینه کاهش توهم (Hallucination) پیشرفت چشمگیری داشته است؛ در مجموعهای از جستجوهای ChatGPT، پاسخهای دارای خطا ۳۰% نسبی کمتر بودهاند. این امر مدل را برای تحلیل، تحقیق و پشتیبانی از تصمیمگیری قابل اعتمادتر میسازد.
GPT 5.2 Thinking در استدلال در بستر طولانی (Long-context reasoning) رکورد جدیدی ثبت کرده است و قادر است انسجام و دقت را در میان اسناد طولانی تا سقف ۲۵۶ هزار توکن حفظ کند. این قابلیت برای تحلیل عمیق اسناد مانند گزارشها و قراردادهای حجیم بسیار حیاتی است.
قیمتگذاری API برای GPT-5.2 به صورت ۱.۷۵ دلار به ازای هر ۱ میلیون توکن ورودی و ۱۴ دلار برای ۱ میلیون توکن خروجی تعیین شده است. با وجود هزینه بالاتر به ازای هر توکن نسبت به نسل قبل، به دلیل کارایی بالاتر توکنها در GPT-5.2، هزینه نهایی دستیابی به سطح مشخصی از کیفیت کمتر تمام میشود.
OpenAI سه نسخه را عرضه کرده است:
GPT 5.2 Instant: مدل سریع و کارآمد برای کار روزمره و نگارش فنی.
GPT 5.2 Thinking: مدل عمیقتر برای کارهای پیچیده، کدنویسی و خلاصهسازی اسناد طولانی.
GPT 5.2 Pro: هوشمندترین و قابل اعتمادترین گزینه برای پرسشهای دشوار و حوزههای تخصصی.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





