
هوش مصنوعی (AI) در پی توسعه سیستمهایی است که میتوانند کارهایی را که قبلاً نیازمند هوش و توانایی اندیشه انسان بود، انجام دهند. این حوزه علمی از رشتههای مختلفی از جمله علوم کامپیوتر، مهندسی، ریاضیات، آمار، روانشناسی و علوم اعصاب استخراج میشود. هدف اصلی این حوزه، ایجاد ماشینهای هوشمندی است که قادر به یادگیری باشند. یادگیری ماشین (machine learning) در ابتدا تحت تأثیر نظریههای یادگیری انسان از روانشناسی و علوم اعصاب بوده و به تدریج به یک زیرشاخه متمایز از هوش مصنوعی تبدیل شده است. یادگیری ماشین یک زیر شاخه از هوش مصنوعی است که به عنوان یک رشته بینابینی در دهه 1980 شناخته شد. تعریف کاملاً پذیرفته شده یادگیری ماشین و کاربردهای بالقوه آن در اختلالات مغزی، هم در محیطهای تحقیقاتی و هم بالینی بررسی میشود. با توجه به رویکردهای متعدد در ماشین لرنینگ، درک طبقهبندی این روشها بسیار مهم است تا مناسبترین رویکرد برای یک تحقیق معین انتخاب شود.
در این مقاله، شما با مفاهیم و کاربردهای مهم یادگیری ماشین در حوزه بررسی اختلالات مغزی آشنا خواهد شد. از ارتباط یادگیری ماشین با علوم شناختی گرفته تا کاربردهای آن در پیشبینی، تشخیص و درمان اختلالات، این مقاله دیدی جامع نسبت به این حوزهی نوظهور ارائه میدهد.
از یادگیری انسان تا یادگیری ماشین
توانایی یادگیری یکی از ویژگیهای اساسی رفتار هوشمند است. ما به عنوان انسان، از روزی که به دنیا میآییم یا حتی قبل از آن، از طریق تعاملات خود با محیط زیست به سختی یاد میگیریم. بنابراین جای تعجب نیست که وقتی تلاش برای ساخت ماشینهای هوشمند آغاز شد، منبع الهام مهمی از آنچه در مورد یادگیری انسان میدانیم سرچشمه گرفت. از آغاز قرن بیستم، روانشناسی و علوم اعصاب سهم قابل توجهی در درک ما از نحوه یادگیری انسانها داشتهاند.
یادگیری ماشین چیست؟
یادگیری ماشین به معنای استخراج الگوها از دادهها و استفاده از این الگوها برای پیشبینی دادههای جدید است. در واقع، ماشین لرنینگ به ماشینها امکان میدهد که از تجربه خود یاد بگیرند و الگوهای پنهان در دادهها را شناسایی کنند تا بتوانند پیشبینی دقیقتری ارائه دهند. این فرایند به ماشینها امکان میدهد که با دقت بیشتری به دادهها پاسخ دهند و عملکرد بهتری داشته باشند.
یادگیری ماشین یعنی ساخت برنامههای رایانهای که به صورت خودکار از تجربیات خود یاد میگیرند و از طریق بهبود عملکرد خود، تغییر میکنند. به عنوان مثال، از این تکنولوژی میتوان برای پیشبینی احتمال ابتلا به بیماری آلزایمر در افراد با اختلال شناختی خفیف (MCI: mild cognitive impairment) استفاده کرد. این پیشبینی ممکن است با استفاده از دادههای مختلف مانند جمعیتشناسی، تصویربرداری عصبی و ژنتیک صورت گیرد. در نتیجه، الگوریتم یادگیری ماشین میتواند از این دادهها برای پیشبینی نتایج بالینی افراد جدید استفاده کند.
یادگیری ماشین به معیار تعمیم پذیری توجه زیادی دارد. این معیار، نشان دهنده قدرت مدل است که بتواند با دادههای جدید، پیشبینیهای صحیح ارائه دهد. این موضوع بسیار مهم است؛ زیرا ما ممکن است دادههای جدیدی را ببینیم که شباهتهایی با دادههای قبلی دارند، اما کاملا یکسان نیستند. بنابراین، ضروری است که مدلهای یادگیری ماشین الگوهای قابل تعمیم را بیاموزند تا بتوانند در مواجهه با دادههای جدید، پیشبینیهای دقیقتری ارائه دهند. به عنوان مثال، اگر الگوریتم بر اساس تفاوتهای جعلی عمل کند، امکان استفاده از آن برای بقیه جمعیت وجود نخواهد داشت. بنابراین، یادگیری الگوهای قابل تعمیم، یک چالش کلیدی در حوزه ماشین لرنینگ است.
ارتباط یادگیری ماشین در تحقیقات اختلالات مغزی
در 30 سال گذشته، پیشرفتهای قابل توجهی در درک اساس عصبی بیولوژیکی اختلالات مغزی، از جمله شرایط روانپزشکی و عصبی، دیده شده است. با این حال، تفسیر این یافتهها به عمل بالینی محدود بوده است، اصلیترین دلیل آن استفاده از روشهایی است که تنها استنتاجها را در سطح گروهی مجاز میکنند. از این روشها به دلیل وجود شکاف بین تحقیقات و عملکرد بالینی استفاده شده است. اما این شکاف با استفاده از یادگیری ماشین که چندین مزیت کلیدی را در زمینه تحقیقات اختلالات مغزی دارد، قابل پر کردن است.
یادگیری ماشین روشی است که به ما امکان میدهد الگوهای مختلف دادهها را بشناسیم. این روش به ما کمک میکند تا بین افراد سالم و افراد مبتلا به بیماریهای خاص تمایز قائل شویم. همچنین، با استفاده از ماشین لرنینگ میتوان به خوبی پیشبینی کرد که یک فرد جدید به کدام گروه تعلق دارد. این روش به ما امکان میدهد تا به تعاملات بین چند متغیر توجه کنیم و حساسیت بیشتری نسبت به تغییرات ظریف و گسترده در ساختار و عملکرد مغز داشته باشیم.
ماشین لرنینگ یک روش آماری جدید است که بر خلاف روشهای سنتی، بر پیشبینی و تعمیمپذیری تمرکز دارد. هدف این روش ساخت مدلهایی است که قادر به پیشبینی دقیق در دادههای دیده نشده باشند. این روش به ویژه در حوزه تحقیقات اختلالات مغزی مفید است، زیرا با دادههای پیچیده و حجم نمونه کوچک نیز میتواند کارایی داشته باشد. اما باید توجه داشت که یادگیری ماشین مسئله تعمیم پذیری را به طور کامل حل نمیکند، بلکه سعی دارد کارایی آن را ارزیابی کند که برای هدف بلندمدت پزشکی شخصی در اختلالات مغزی ضروری است.
تا به حال تحقیقات اختلالات مغزی بر اساس نظریههای پیشین انجام میگرفت. اما با پیشرفت تکنولوژی و دسترسی به دادههای بزرگ، محققان از مدلهای دادهمحور استفاده میکنند. هرچند که دادههای بزرگ هنوز در تمام تحقیقات اختلالات مغزی مورد استفاده قرار نمیگیرند، اما ابزارهایی مانند تصویربرداری عصبی و کنسرسیومهای ژنتیکی منجر به افزایش چشمگیر تعداد نمونهها شدهاند و استفاده از یادگیری ماشین در تحلیل دادههای بزرگ نقش مهمی دارد.
در حوزه یادگیری ماشین، تغییرپذیری فردی به میزان تفاوتهایی اشاره دارد که بین افراد در پاسخ به یک مدل یا درک یک مفهوم وجود دارد. این تفاوتها میتوانند در تشخیص بیماریهای روانپزشکی و عصبی نقش مهمی ایفا کنند. ادغام این تفاوتها در مدلسازی چالشهایی را به وجود میآورد، اما استفاده از دادههای بزرگ میتواند در تفسیر بهتر و کاربرد بالینی مفید باشد.
در نتیجه، ادغام یادگیری ماشین در تحقیقات مربوط به اختلالات مغزی نویدبخش پر کردن شکاف بین یافتههای تحقیق و عملکرد بالینی است. یادگیری ماشین با فعال کردن استنتاجهای سطح فردی، در نظر گرفتن روابط چند متغیره، تمرکز بر پیشبینی و تعمیمپذیری، استفاده از دادههای بزرگ و تشخیص ناهمگونی، راههای جدیدی برای پزشکی شخصیسازی شده و تصمیمگیری بهبودیافته در تشخیص و درمان اختلالات مغزی ارائه میدهد.
این رویکرد دگرگونکننده با ارائه ابزارهای جدید برای تصمیمگیری آگاهانه و پیشبرد هدف بلندمدت پزشکی شخصی در اختلالات مغزی، به طور قابلتوجهی بر این حوزه تأثیر میگذارد.
انواع مختلف یادگیری ماشین
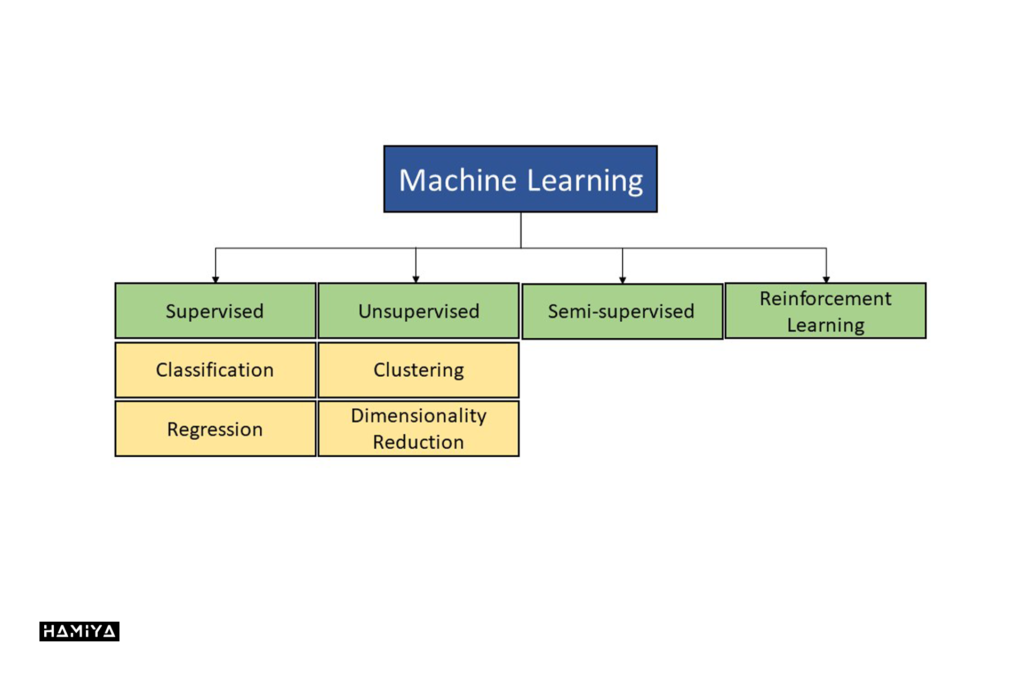
همانطور که پیشتر در این مقاله گفته شد، یادگیری ماشین شامل یادگیری الگوهای مرتبط در دادهها و سپس استفاده از آنها برای پیشبینی است. روشهای مختلفی برای یادگیری ماشین وجود دارند که بر اساس سبک یادگیری، به چهار نوع مختلف ماشین لرنینگ تقسیم میشوند:
- تحت نظارت
- بدون نظارت
- نیمه نظارت
- یادگیری تقویتی
به طور کلی یادگیری تحت نظارت به عنوان متداولترین روش در تحقیقات اختلالات مغزی نیز مورد استفاده قرار میگیرد و جزئیات بیشتری از انواع روشهای ماشین لرنینگ مورد بحث قرار میگیرد.
یادگیری تحت نظارت (Supervised Learning)
در یادگیری نظارت شده، الگوریتم به “متغیر هدف” که همان چیزی است که می خواهد پیش بینی کند، دسترسی دارد. این متغیر میتواند مثلاً وجود یا عدم وجود بیماری، شدت علائم، یا پیامد بالینی آینده باشد. هدف در این نوع یادگیری، استفاده از یک الگوریتم برای یادگیری تابع بهینه است که بهترین رابطه بین ورودی و متغیر هدف را به خوبی بررسی کند. الگوریتم، با استفاده از چندین مثال، آموزش میبیند و در طول فرآیند یادگیری اجازه میدهد که بر اساس نزدیکی پیشبینیهای خود به مقدار واقعی هدف، بازخورد دریافت کند. این نوع یادگیری اغلب با یادگیری با معلم مقایسه میشود، زیرا معلم پاسخهای صحیح را میداند و زمانی که الگوریتم اشتباه میکند، آن را اصلاح میکند. در نهایت، عملکرد الگوریتم با مقایسه پیشبینیها با مقادیر واقعی هدف در دادههای شناخته نشده اندازهگیری میشود.
طبقه بندی (Classification)
الگوریتمهای طبقهبندی به عنوان یک روش برای پیشبینی عضویت افراد در گروههای مختلف شناخته میشوند. این الگوریتمها برای تحلیل مشاهدات و دادهها استفاده میشوند و در بسیاری از موارد، به عنوان ابزاری مؤثر برای تشخیص اختلالات مغزی مورد استفاده قرار میگیرند. یکی از کاربردهای رایج الگوریتمهای طبقهبندی در حوزه اختلالات مغزی، طبقهبندی تشخیصی است که به وسیله آن، الگوریتمها یاد میگیرند که چگونه بین افراد سالم و افراد مبتلا به بیماریهای خاص تمایز قائل شوند. همچنین، این الگوریتمها برای پیشبینی پیامدهای طولانی مانند پیشرفت بیماری یا عکس العمل درمانی در بیماران نیز استفاده میشوند. به طور کلی، الگوریتمهای طبقهبندی از دادههای تصویربرداری عصبی، علائم حرکتی و اطلاعات ژنتیکی برای شناسایی افراد مبتلا به اختلالات مغزی استفاده میکنند.
رگرسیون (Regression)
الگوریتم رگرسیون یک الگوریتم مهم در حوزه یادگیری ماشین است که بیشتر برای پیشبینی امتیاز یا مقدار پیوسته استفاده میشود. این الگوریتم میتواند در پیشبینی نتایج بالینی مانند سطح عملکرد در افراد با خطر بالای روانپریشی، نمرات بالینی در افراد مبتلا به آلزایمر یا اختلالات طیف اوتیسم و حتی پیشرفت علائم در بیماری هانتینگتون مورد استفاده قرار بگیرد. این الگوریتم از دادههای بالینی استفاده میکند و با دقت بالا میتواند نتایج مفیدی را پیشبینی کند.
یادگیری بدون نظارت (Unsupervised Learning)
برخلاف یادگیری تحت نظارت، در یادگیری بدون نظارت، هیچ مقدار و ارزش هدفی وجود ندارد. هدف، بیشتر کشف ساختارهای زیربنایی در دادهها است. دو کاربرد اصلی یادگیری بدون نظارت برای تحقیقات اختلالات مغزی عبارتند از: خوشه بندی و کاهش ابعاد (فروکاهی ابعاد).
خوشه بندی (Clustering)
تجزیه و تحلیل خوشهای یک روش تحلیلی است که برای دستهبندی زیرگروههای معنیدار از یک مجموعه داده بزرگ به کار میرود. به عنوان مثال، این روش میتواند افراد را بر اساس ویژگیهای مشترکی که در آنها مشاهده میشود، به گروههای کوچکتر و منحصربهفرد تقسیم کند. این روش بر خلاف دستهبندیهای سنتی، افراد را بر اساس ویژگیهای خاص و شباهتهای مشاهده شده در آنها دستهبندی میکند. کاربردهای این روش در تحقیقات اختلالات مغزی شامل بررسی ویژگیهای عصبی-شناختی بیماران مبتلا به اختلالات دوقطبی یا تشخیص بیماران با یا بدون اختلالات طیف اوتیسم از طریق سوابق الکترونیکی سلامت است.
فروکاهی ابعاد (Dimensionality Reduction)
کاهش ابعاد (فروکاهی بعد) در شرایطی مفید است که تعداد ویژگیها و مشخصهها به طور قابل ملاحظهای بیشتر از تعداد مشاهدات باشد. وقتی تعداد ویژگیها و مشخصهها بسیار بیشتر از تعداد مشاهدات باشد، این مشکل به عنوان “معضل ابعاد” (curse of dimensionality) شناخته میشود. در چنین شرایطی، کاهش تعداد ویژگیها میتواند برای کاهش نیازهای محاسباتی، حذف اطلاعات اضافی یا نامربوط و کاهش خطر بیش از حد مناسب مفید باشد. برای انجام کاهش ابعاد، میتوان از تکنیکهای مختلفی مانند PCA (principal component analysis) و تجزیه و تحلیل مؤلفه مستقل استفاده کرد. PCA به عنوان یکی از روشهای رایج برای کاهش ابعاد در اختلالات مغزی شناخته میشود.
یادگیری نیمه نظارتی (Semi-supervised Learning)
یادگیری نیمه نظارتی به معنای استفاده از دادههای برچسب گذاری شده و بدون برچسب در مدل سازی دادهها است. این روش میتواند در مواردی که برچسب گذاری دادهها زمان بر و یا پرهزینه باشد، استفاده شود. یکی از مثالهای این روش، مطالعات طولانی مدت در بیماریهایی است که نیازمند زمان و هزینه زیادی برای برچسب گذاری بیماران است. استفاده از یادگیری نیمه نظارتی در این موارد میتواند به دقت و کارایی مدلها کمک کند. هر چند که استفاده از این روش در اختلالات مغزی رایج نیست، اما نتایج مطالعات نشان میدهد که استفاده از یادگیری نیمه نظارتی میتواند نتایج بهتری نسبت به روشهای سنتی داشته باشد.
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی یک روش ماشین لرنینگ است که در آن سیستم یاد میگیرد که چگونه بر اساس واکنشهای محیط خود رفتار کند. این نوع یادگیری بر اساس پاداش و مجازات است که سیستم برای بهبود عملکرد خود از آنها استفاده میکند. یادگیری تقویتی به دلیل کاربردهای گستردهای که در در زمینههای مختلف دارد، به عنوان یکی از مهمترین حوزههای یادگیری ماشین تلقی میشود. اما در حوزه اختلالات مغزی، استفاده از این نوع یادگیری هنوز به محدودیتهای زیادی برخورد کرده است.
با توجه به مطالب ارائه شده در این مقاله، میتوان نتیجه گرفت که ماشین لرنینگ یک رویکرد بسیار نویدبخش برای پیشبرد تحقیقات و کاربردهای بالینی در زمینه اختلالات مغزی و سایر زمینههاست است. این فناوری با ارائه ابزارهایی برای شناسایی الگوها، پیشبینی نتایج و تصمیمگیری بهینه، میتواند در هر دو حوزه پژوهشی و بالینی مفید واقع شود. البته همچنان چالشهایی در این زمینه وجود دارد که نیازمند مطالعات بیشتر است، اما آینده روشنی برای ادامه پیشرفتها در این حوزه وجود دارد.





