
هوش مصنوعی در حال تغییر چهره دنیای ما است. از کمک به تشخیص بیماریها گرفته تا بهینهسازی عملیات تجاری، هوش مصنوعی به سرعت در حال نفوذ به تمام جنبههای زندگی ماست. در قلب این انقلاب فناوری، مدلهای یادگیری ماشین قرار دارند. الگوریتمهای پیچیدهای که میتوانند از دادهها یاد بگیرند و پیشبینیهای دقیق ارائه دهند.
مقدمهای بر یادگیری ماشین: از نظریه تا عمل – راهی نوین برای پژوهشهای اختلالات مغزی
اما آیا میدانید که مدلهای یادگیری ماشین انواع مختلفی دارند که هر کدام برای کاربردهای خاصی مناسب هستند؟ از یادگیری تحت نظارت که در آن، مدل از دادههای برچسبدار آموزش میبیند، تا یادگیری بدون نظارت که الگوها را در دادههای خام شناسایی میکند، هر نوع مدل منحصر به فرد، مزایا و معایب خاص خود را دارد. انتخاب مدل مناسب میتواند تفاوت بین موفقیت و شکست یک پروژه هوش مصنوعی را رقم بزند.
در این مقاله، به معرفی و توضیح کلی انواع مدلهای یادگیری ماشین و هوش مصنوعی پرداخته شده است. با این حال، لازم است به شما خوانندگان گرامی اطمینان دهیم که در آیندهی نزدیک، مجموعه مقالات جامعتری از هامیا ژورنال منتشر خواهد شد که در آن، هر یک از این مدلها و روشها به طور کامل و با جزئیات بیشتری تشریح خواهد شد. بنابراین، از شما دعوت میکنیم تا با مجله اینترنتی فروشگاه آنلاین هامیا همراه باشید و منتظر دریافت اطلاعات دقیقتر و کاربردیتر در این زمینه پرطرفدار باشید. هدف ما ارائهی دانشی کامل و بروز در مورد جدیدترین پیشرفتهای یادگیری ماشین و هوش مصنوعی است تا بتوانید از این فناوریها به بهترین شکل ممکن بهره ببرید.
مدلهای یادگیری ماشین چیست؟
مدلهای یادگیری ماشین، فرآیندهایی هستند که به طور خودکار، الگوها و روابط پنهان در دادهها را شناسایی میکنند. این مدلها از ترکیبی از دادههای برچسبدار و بدون برچسب استفاده میکنند و از طریق الگوریتمهای مختلف یادگیری ماشین، بهترین تناسب را برای حل یک مسئله خاص پیدا میکنند.
مایکل شهاب (Michael Shehab)، مدیر کل و رهبر فناوری و نوآوری آزمایشگاهی در PwC1، توضیح میدهد که هر الگوریتم یادگیری ماشین، استراتژی خاصی را برای کشف الگوها در مجموعه دادههای تاریخی به کار میگیرد. تبدیل این الگوریتمها به مدلها شامل سه مرحله است:
- تعریف مسئله
- شناسایی هدف خاص
- ارائه بازخورد برای هدایت جستجوی الگوریتم برای یافتن راهحل
به گفتهی شهاب:
مدل نهایی، تابعی را نشان میدهد که توسط الگوریتم یادگیری ماشین آموخته شده و میتواند نمونههای جدید را به خروجیهای دقیق نگاشت کند.
Michael Shehab
انتخاب نوع مدل، آمیزهای از هنر و علم است. بریان استیل (Brian Steele)، معاون مدیریت محصول در Gryphon.ai، میگوید:
رویکرد یکسانی برای تشخیص اینکه کدام مدل برای سازمان شما مناسب است، وجود ندارد. هر مدل، بینشها و نتایج متفاوتی را بر اساس نوع داده و کاربرد آن ارائه میدهد. همچنین، نوع و کیفیت دادههای ورودی، انتخاب انواع خاصی از مدلها را تعیین میکند.
Brian Steele
انواع مدلهای یادگیری ماشین
حوزه یادگیری ماشین به سرعت در حال پیشرفت است. هنگامی که به توصیف رویکردهایی مانند آنچه در کاربردهای هوش مصنوعی مولد استفاده میشود میرسیم، تکنیکهای جدید باعث میشوند که روشهای قدیمی طبقهبندی مدلها کنار گذاشته شوند.
هوش مصنوعی مولد (Generative AI) چیست؟ تمام آنچه را که نیاز است تا بدانید!
آنانتا سکار (Anantha Sekar)، سرپرست هوش مصنوعی در Tata Consultancy Services، میگوید که هیچ استاندارد پذیرفته شدهای برای طبقهبندی وجود ندارد؛ زیرا مدلهای تازهای روزانه معرفی میشوند. با این حال، رایجترین طبقهبندی مدلهای یادگیری ماشین شامل چهار دسته اصلی است:
- یادگیری با نظارت (Supervised Learning)
- یادگیری نیمه نظارتی (Semi-Supervised Learning)
- یادگیری بدون نظارت (Unsupervised Learning)
- یادگیری تقویتی (Reinforcement Learning)
سکار توصیه میکند که همه این انواع اصلی باید همراه با رویکرد هدف و نوع یادگیری مورد استفاده در نظر گرفته شوند.
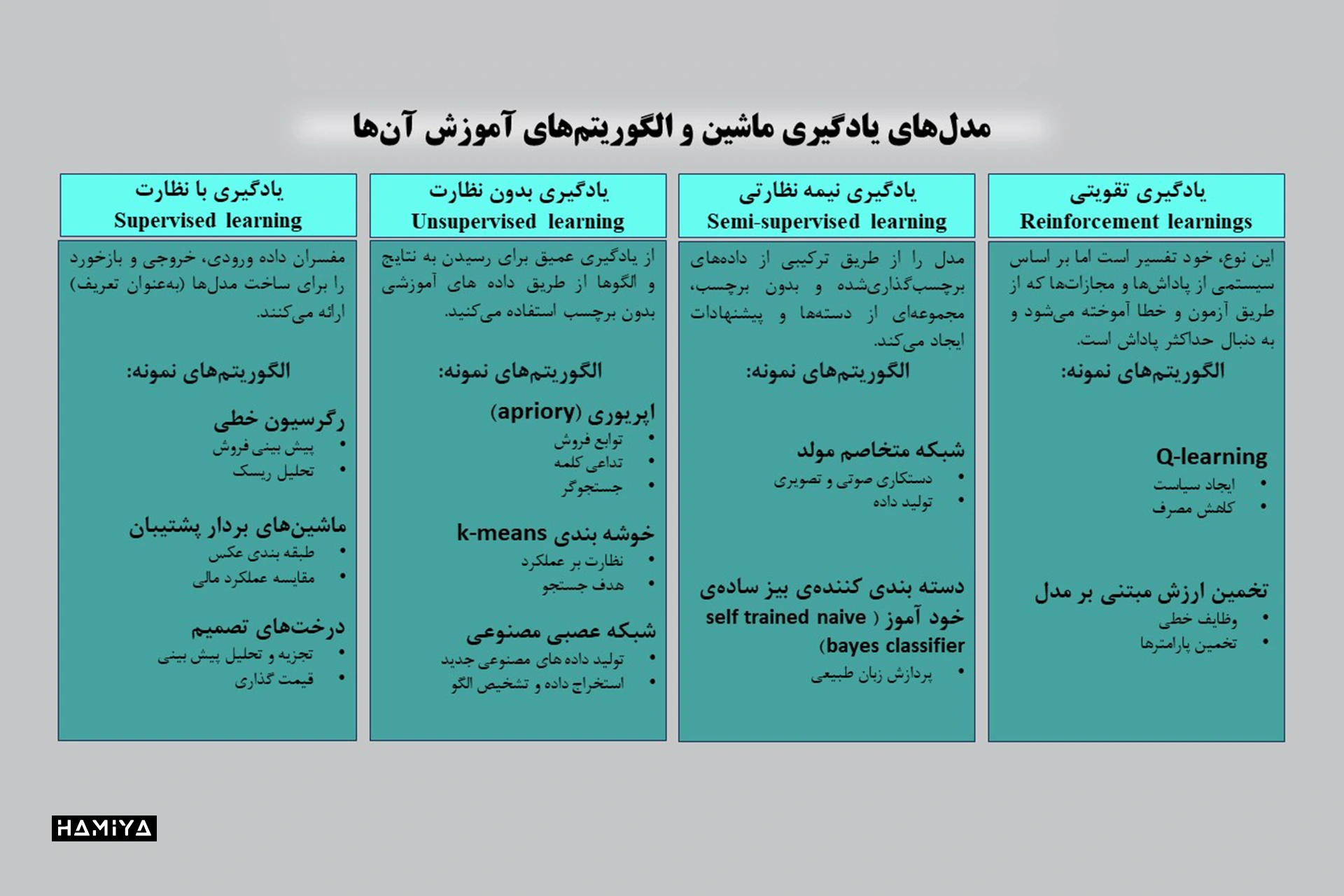
به عنوان مثال، یک مدل هوش مصنوعی مولد ممکن است شامل چندین رویکرد آموزشی باشد که به صورت زنجیرهای به کار گرفته میشوند. ممکن است با یادگیری بدون نظارت بر روی یک مجموعه بزرگ از دادهها آغاز شود، سپس از یادگیری تحت نظارت برای تنظیم دقیق مدل استفاده کند و در نهایت از یادگیری تقویتی برای تنظیم مداوم نتایج پس از استقرار بهره ببرد. سکار خاطر نشان میکند:
بحث درباره انواع مدلها، مانند بحث درباره انواع انسانهاست. از آنجایی که هر مدل در نهایت منحصر به فرد است، طبقهبندیها عمدتاً برای اهداف درک گسترده مفید هستند.
Anantha Sekar
آموزش مدلهای یادگیری ماشین
دانشمندان داده رویکردهای متفاوتی را برای آموزش مدلهای یادگیری ماشین توسعه میدهند. فرآیند آموزش به طور معمول با تهیه دادهها، شناسایی موارد استفاده، انتخاب الگوریتمهای آموزشی و تجزیه و تحلیل نتایج آغاز میشود. مایکل شهاب از PwC مجموعهای از بهترین شیوهها را برای توسعه مدلها ارائه میکند:
- ساده شروع کنید. آموزش مدل باید با سادهترین رویکرد ممکن آغاز شود. سپس میتوان پیچیدگی را با افزودن ویژگیهای پیچیدهتر و الگوریتمهای پیشرفتهتر به مدل اضافه کرد. مدل ساده، نقطه شروعی برای ارزیابی این است که آیا پیچیدگی اضافی، ارزش زمان و هزینه صرف شده را دارد یا خیر.
- یک فرآیند توسعه مدل منسجم ایجاد کنید. با توجه به ماهیت تکراری این فرآیند، باید از ابزارهایی استفاده شود که ردیابی جامعی از آزمایشها را ارائه میدهند تا دانشمندان داده بتوانند به راحتی نقاط قابل بهبود مدل را شناسایی کنند.
- مشکل مناسب را شناسایی کنید. اهداف تعریف نشده، حوزههای نامناسب و انتظارات غیرواقعی همگی میتوانند منجر به عملکرد ضعیف مدل یا ایجاد ارزش ناکافی شوند. مدلسازی نیازمند زمینه محکمی برای ارزیابی صحیح توسعه آن است.
- اطلاعات تاریخی را درک کنید. کارایی مدل به دادههایی که روی آن آموزش دیده بستگی دارد. بنابراین درک دقیق رفتار دادهها، کیفیت و کامل بودن آنها، روندهای مهم و هرگونه تعصب احتمالی ضروری است.
- از دقت اطمینان حاصل کنید. برای جلوگیری از سوگیری، بازخورد نامناسب یا تقویت رفتار اشتباه، باید معیارهای قابل اندازهگیری برای عملکرد مدل تعیین شود. الگوریتم، از طریق بازخورد از نتایج دادههای آموزشی یاد میگیرد. اگر مقادیر بازخوردی دقیق نباشند، نتیجه میتواند یک مدل ضعیف باشد.
- روی توضیحپذیری تمرکز کنید. دانشمندانی که روی چرایی عملکرد مدل تمرکز میکنند، مدلهای بهتری خواهند ساخت. این رویکرد نیازمند اعتبارسنجی و آزمایش جامعتری است. توضیحپذیری بینشی درباره نقاط ضعف و راههای بهبود عملکرد مدل ارائه میدهد و اعتماد مصرفکنندگان را جلب میکند.
- آموزش را ادامه دهید. آموزش مدل یک فرآیند مداوم است که حتی پس از مرحله تولید نیز باید ادامه یابد تا مدل به طور مستمر بهبود یابد.
آیا بهترین مدل یادگیری ماشین وجود دارد؟
به طور کلی، “بهترین مدل” برای همه موارد یادگیری ماشین وجود ندارد. همانطور که آنانتا سکار (Anantha Sekar) توضیح میدهد، برای هر مشکل یا کاربرد خاص، مدلهای مختلفی وجود دارند که میتوانند به شکل بهینهای عمل کنند. بینشهای حاصل از آزمایش با دادهها ممکن است به انتخاب یک مدل متفاوت منجر شود. همچنین الگوهای دادهها در طول زمان تغییر میکنند و یک مدل که در ابتدا خوب عمل میکند، ممکن است با مدل دیگری جایگزین شود.
سکار میگوید یک مدل خاص را میتوان تنها برای یک کاربرد یا مجموعه داده در یک نقطه زمانی خاص، به عنوان “بهترین” در نظر گرفت. کاربردهای مختلف میتوانند نیازهای متفاوتی داشته باشند؛ برخی به دقت بالا نیاز دارند، برخی به اطمینان بیشتر و برخی به توضیحپذیری. محدودیتهای محیطی مانند حافظه، توان و عملکرد نیز باید در نظر گرفته شوند.
دانشمندان داده همچنین باید جنبههای عملیاتی مدلها پس از استقرار (ModelOps) را در اولویتبندی یک مدل در نظر بگیرند؛ مانند پردازش دادههای خام، تنظیم دقیق، مهندسی پرامپت و کاهش توهمات هوش مصنوعی. همانطور که سکار توصیه میکند:
انتخاب بهترین مدل برای یک موقعیت خاص، کار پیچیدهای است که جنبههای تجاری و فنی زیادی را باید مد نظر قرار داد.
Anantha Sekar
مدل یادگیری ماشین در مقابل الگوریتم یادگیری ماشین
اگرچه گاهی اوقات اصطلاحات “مدل یادگیری ماشین” و “الگوریتم یادگیری ماشین” به یک معنا به کار میروند، اما از دیدگاه علم داده، این دو مفهوم کاملاً متفاوت هستند. الگوریتمهای یادگیری ماشین برای آموزش مدلهای یادگیری ماشین مورد استفاده قرار میگیرند.
به گفته بریان استیل (Brian Steele)، الگوریتمهای یادگیری ماشین “مغز” مدلها هستند. آنها شامل کدهایی هستند که برای پیشبینیهای مدلها استفاده میشوند. دادههایی که الگوریتمها روی آنها آموزش میبینند، اغلب نوع خروجیهایی را که مدلها تولید میکنند، تعیین میکنند. دادهها به عنوان منبع اطلاعاتی برای الگوریتم عمل میکنند تا از آن یاد بگیرد، بنابراین مدلها میتوانند خروجیهای قابل فهم و مرتبط ایجاد کنند.
آنانتا سکار (Anantha Sekar) توضیح میدهد که یک الگوریتم مجموعهای از دستورالعملهاست که نحوه انجام یک کار را توصیف میکند، در حالی که یک مدل یادگیری ماشین، نمایش ریاضی یک مسئله دنیای واقعی است که با الگوریتمهای یادگیری ماشین آموزش دیده است. او میگوید: “بنابراین، مدل یادگیری ماشین یک نمونه خاص است، در حالی که الگوریتمهای یادگیری ماشین مجموعهای از روشها برای نحوه آموزش مدلهای یادگیری ماشین هستند.”
الگوریتم، شکل و تأثیر عملکرد مدل را تعیین میکند. مدل به ماهیت (“چه” بودن) مسئله میپردازد، در حالی که الگوریتم “چگونگی” رسیدن به عملکرد مطلوب مدل را ارائه میدهد. داده، سومین عنصر مرتبط است، زیرا الگوریتم از “دادههای آموزشی” برای آموزش مدل یادگیری ماشین استفاده میکند. بنابراین در عمل، خروجی یادگیری ماشین به مدل، الگوریتمها و دادههای آموزشی بستگی دارد.
- PricewaterhouseCoopers International Limited یک برند خدمات حرفهای چند ملیتی متشکل از شرکتها است که به صورت مشارکتی تحت نام تجاری PwC فعالیت میکند. این برند، دومین شبکه بزرگ خدمات حرفهای در جهان است و به همراه Deloitte، EY و KPMG یکی از چهار شرکت بزرگ حسابداری محسوب میشود. ↩︎





