
در سال 2017، تیم محققان گوگل با انتشار مقالهای با عنوان “Attention is All You Need”، معماری نوینی از شبکههای عصبی مصنوعی به نام “ترانسفورماتور” را معرفی کردند. این مدل به دلیل توانایی منحصر به فردش در پردازش دادههای زبانی و چندوجهی، به یکی از پایههای اصلی هوش مصنوعی امروزی تبدیل شد. تیم نویسندگان هامیا ژورنال در دسته هوش مصنوعی، با مطالعه دقیق این مقاله، به بررسی مدل ترنسفورمر و تاثیرات شگرف آن در توسعه مدل های زبانی بزرگ (LLM) و تحولاتی که در عرصه فناوری و هوش مصنوعی ایجاد کردهاست، پرداختهاند. ترانسفورماتور به عنوان زیرساخت اصلی مدلهای پیشرفتهای چون ChatGPT و DALL-E، توانسته مسیر هوش مصنوعی را به سوی درک بهتر و پردازش زبان طبیعی (NLP) و تعاملات پیچیده باز کند.
این فناوری چگونه توانسته با مدل های مختلفی مانند GPT-4o پیوند خورده و کارکردهایی نظیر مکالمات طبیعی و پردازش متون را بهبود بخشد؟ و آیا ترنسفورمرها تنها در حوزه زبان باقی ماندهاند یا کاربردهای گستردهتری در علوم دیگر پیدا کردهاند؟ در این مقاله، به طور دقیق به این مسائل پرداخته و ارتباط فناوری ترانسفورماتور با چتباتهای هوش مصنوعی مانند GPT-4o بررسی خواهد شد.
ساختار مقاله حاضر شامل معرفی مدل ترنسفورمر، بررسی اصول فنی و کاربردهای آن در زمینههای مختلف میباشد. همچنین به بررسی پیوند این مدل با چتباتها و دیگر فناوریهای مرتبط با هوش مصنوعی پرداخته و نقشهای روشن از مسیر پیشرفت این فناوری برای خواننده ترسیم خواهد شد.
فهرست مطالب
- مدل ترانسفورماتور چیست؟
- مدل ترنسفومر چکارهایی میتواند انجام دهد؟
- معماری مدلهای ترانسفورماتور
- آموزش مدلهای ترنسفومر
- دو نوآوری بزرگ در مدلهای ترانسفورماتور
- مدل ترنسفومر چگونه کار میکند؟
- 1. تعبیهی ورودی (Input embeddings):
- 2. رمزگذاری موقعیتی (Positional encoding):
- 3. توجه چندسر (Multi-head attention):
- 4. نرمالسازی لایه و اتصالات باقیمانده (Layer normalization and residual connections):
- 5. شبکههای عصبی پیشخور (Feedforward neural networks):
- 6. لایههای انباشته (Stacked layers):
- 7. لایه خروجی (Output layer):
- 8. آموزش (Training):
- 9. استنتاج (Inference):
- کاربردهای مدل ترانسفورماتور
- پیاده سازی مدلهای ترنسفومر
مدل ترانسفورماتور چیست؟
مدل ترانسفورماتور یک نوع معماری شبکه عصبی است که به طور خاص برای تبدیل خودکار یک نوع داده به نوع دیگری طراحی شدهاست. این مفهوم در سال 2017 توسط محققان گوگل معرفی شد. هدف اصلی آنها یافتن روشی کارآمدتر برای آموزش شبکههای عصبی جهت ترجمه زبانها بود. با استفاده از مدل ترنسفورمر، محققان توانستند ترجمه انگلیسی به فرانسوی را با دقت بسیار بالاتر و در زمانی بسیار کوتاهتر نسبت به روشهای قبلی انجام دهند.
تحقیقات بعدی نشان داد که کاربرد مدلهای ترانسفورماتور بسیار فراتر از ترجمه زبان میباشد. این مدلها قابلیتهای متنوعی از جمله تولید متن، ایجاد تصاویر و حتی تولید دستورالعمل برای رباتها را دارا هستند. علاوه بر این، ترنسفورمرها میتوانند روابط پیچیده بین انواع مختلف دادهها را مدلسازی کنند. به عنوان مثال، میتوانند دستورالعملهای زبان طبیعی را به تصاویر یا کدهای برنامهنویسی تبدیل کنند. این قابلیت به عنوان هوش مصنوعی چند وجهی شناخته می شود.
مدلهای ترنسفورمر نقش بسیار مهمی در توسعه مدلهای بزرگ زبانی (LLM) ایفا میکنند. بسیاری از سیستمهای هوش مصنوعی پیشرفته مانند claude، موتور جستجوی گوگل، ابزار تولید تصویر Dall-E و دستیار برنامهنویسی Microsoft Copilot بر پایه معماری ترانسفورماتور ساخته شدهاند. این مدلها به دلیل توانایی در پردازش حجم عظیمی از دادهها و درک پیچیدگیهای زبان طبیعی، به ابزاری قدرتمند در حوزه هوش مصنوعی تبدیل شدهاند.
امروزه، مدلهای ترانسفورماتور به هسته اصلی بسیاری از کاربردهای پردازش زبان طبیعی تبدیل شدهاند. دلیل این امر عملکرد بسیار بهتر آنها نسبت به روشهای قبلی است. علاوه بر این، محققان دریافتهاند که ترنسفورمرها قابلیتهای فراتری از زبان را نیز دارند. آنها میتوانند در حوزههای مختلفی مانند شیمی، زیستشناسی و پزشکی به کار گرفته شوند و وظایفی مانند پیشبینی ساختار پروتئین و تحلیل دادههای پزشکی را انجام دهند.
یکی از کلیدهای موفقیت مدلهای ترانسفورماتور، مفهومی به نام “توجه” میباشد. این مکانیزم به مدل اجازه میدهد تا اهمیت کلمات مختلف در یک جمله را تعیین کند و روابط بین آنها را بهتر درک کند. به عنوان مثال، ترنسفورمر میتواند با توجه به کلمات اطراف، معنای یک کلمه خاص را بهتر بفهمد یا حتی میتواند ارتباط بین کلمات و عناصر دیگری مانند تصاویر یا ساختارهای شیمیایی را شناسایی کند.
مفهوم “توجه” از دهه 1990 شناخته شده بود، اما کاربرد آن در مدلهای ترانسفورماتور تحولی بزرگ ایجاد کرد. محققان گوگل در سال 2017 نشان دادند که میتوان از مکانیزم توجه برای رمزگذاری مستقیم معنای کلمات و ساختار زبان استفاده کرد. این رویکرد جدید، نیاز به مراحل اضافی پردازش را از بین برد و به مدلها اجازه داد تا انواع مختلف دادهها را به صورت یکپارچه پردازش کنند. این پیشرفت، راه را برای توسعه مدل های بسیار قدرتمند و پیچیده در سالهای اخیر هموار کردهاست.
مدل ترنسفومر چکارهایی میتواند انجام دهد؟
مدلهای ترنسفورمر به سرعت جایگزین معماریهای سنتی شبکههای عصبی مانند شبکههای عصبی بازگشتی (RNNها) و شبکههای عصبی کانولوشنال (CNNها) شدهاند که در مقالات یادگیری ماشین و یادگیری عمیق به مفصل تشریح شدهاند. RNNها برای پردازش دادههای متوالی مانند متن یا صدا مناسب بودند، اما در پردازش دنبالههای طولانی محدودیت داشتند. ترانسفورماتورها این محدودیت را برطرف کرده و قادرند دنبالههای طولانیتر را به طور موازی و میتوانند هر کلمه یا توکن را به صورت موازی پردازش کنند، که این امر منجر به افزایش کارایی و سرعت آنها میشود.
CNNها نیز در زمینه پردازش تصاویر بسیار موفق بودند. این شبکهها برای مقایسه نواحی نزدیک به هم در تصاویر طراحی شدهاند. در مقابل، ترانسفورماتورهایی مانند Vision Transformer که در سال 2021 معرفی شد، قادرند ارتباطات بین نواحی دورتری از تصویر را نیز برقرار کنند و در نتیجه درک بهتری از محتوای تصویر پیدا کنند. علاوه بر این، ترنسفورمرها در کار با دادههای برچسبنشده نیز عملکرد بهتری دارند.
مروری بر فناوری دیپ فیک، کاربردها و روشهای شناسایی آن
ترانسفورماتورها با استفاده از مجموعههای عظیمی از دادههای برچسبنشده، میتوانند به طور خودکار معنای متن را درک کنند. این قابلیت به محققان اجازه میدهد تا مدلهای ترنسفورمر را با مقیاس بسیار بزرگتری (صدها میلیارد و حتی تریلیونها پارامتر) آموزش دهند. البته، مدل های از پیش آموزشدیده تنها نقطه شروع هستند و برای انجام وظایف خاص، نیاز به تنظیم دقیق با استفاده از دادههای برچسبدار دارند. با این حال، این مرحله تنظیم دقیق نسبت به مرحله آموزش اولیه، به منابع محاسباتی کمتری نیاز دارد.
معماری مدلهای ترانسفورماتور
مدلهای ترانسفورماتور از دو بخش اصلی رمزگذار (encoding) و رمزگشا (decoding) تشکیل شدهاند که با همکاری یکدیگر به پردازش اطلاعات میپردازند. قلب تپندهی این مدلها، مکانیسم توجه میباشد که به ترنسفورمرها اجازه میدهد تا اهمیت کلمات و توکنهای مختلف را در یک جمله ارزیابی کنند. به لطف این مکانیسم، ترانسفورماتورها قادرند تمامی کلمات را با در نظر گرفتن پنجره کانالی به طور همزمان پردازش کنند و به همین دلیل، به توسعه مدل های زبانی بزرگ کمک شایانی کردهاند.
به لطف مکانیزم توجه، رمزگذار در ترنسفورمر، هر کلمه یا توکن را به یک بردار (vector) تبدیل میکند. اهمیت هر کلمه در این بردار، تحت تأثیر کلمات دیگر در جمله قرار میگیرد. به عنوان مثال، به دو جملهی زیر توجه کنید:
“علی آب داخل پارچ را داخل لیوان ریخت و آن را پر کرد.”
در این جمله، فعل “پر کرد” نشان میدهد که لیوان کاملاً از آب پر شدهاست. بنابراین، مکانیسم توجه به کلمه “پر کرد” وزن بیشتری میدهد و معنای “آن” را به عنوان “لیوان پر شده” تفسیر میکند. اما در جملهی زیر:
“علی آب داخل پارچ را داخل لیوان ریخت و آن را خالی کرد”
کلمه “خالی کرد” نشان میدهد که پارچ پس از ریختن آب، خالی شدهاست. در این حالت، مکانیسم توجه به کلمه “خالی کرد” وزن بیشتری میدهد و معنای “آن” را به عنوان “پارچ خالی” تفسیر میکند.
رمزگشا در واقع کار عکس رمزگذار را انجام میدهد. مثلاً در ترجمه ماشینی، رمزگشا کلمات زبان مبدا را به کلمات زبان مقصد تبدیل میکند. این مکانیسم نه تنها برای ترجمه بین زبانها، بلکه برای انجام وظایفی مانند خلاصهسازی متن نیز قابل استفاده است. به عنوان مثال، میتوان از ترانسفورماتور برای تبدیل یک مقاله طولانی به یک خلاصه کوتاه استفاده کرد.
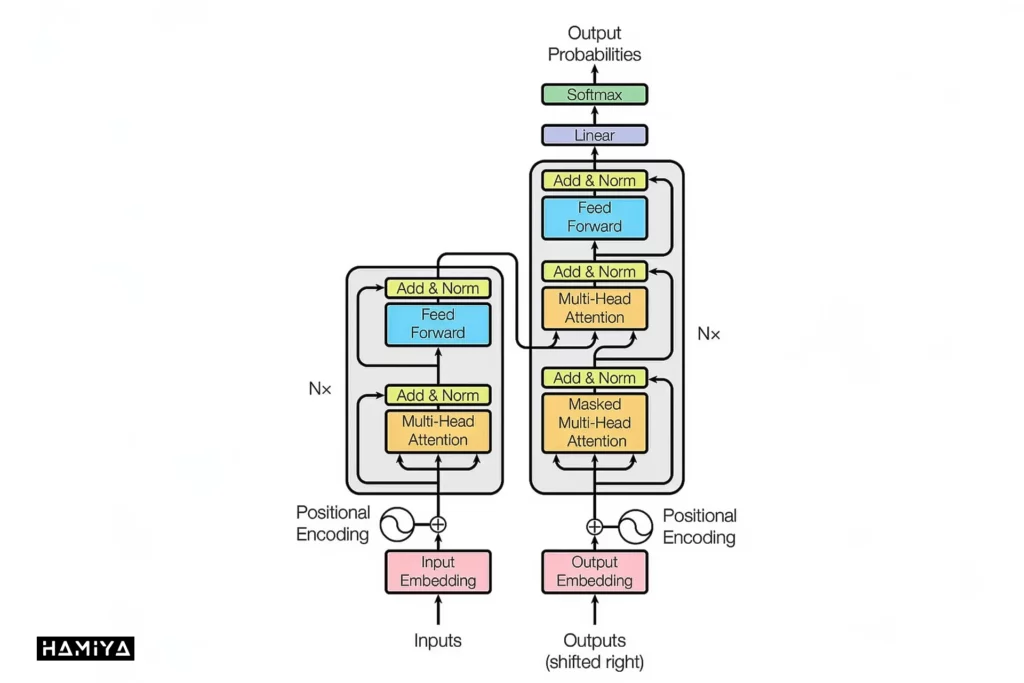
آموزش مدلهای ترنسفومر
آموزش یک ترانسفورماتور شامل دو مرحله کلیدی میباشد. در مرحله اول، یک ترنسفورمر مجموعهای بزرگ از دادههای برچسبنشده را پردازش میکند تا ساختار زبان یا پدیدههای دیگر، مانند تاخوردگی پروتئین و نحوه تأثیرگذاری عناصر نزدیک به یکدیگر را یاد بگیرد. این یک مرحله پرهزینه و انرژیبر است به طوری که آموزش برخی از بزرگترین مدلها میتواند میلیونها دلار هزینه داشته باشد.
پس از آموزش اولیه، مدل برای انجام وظایف خاص تنظیم می شود که این فرایند تنظیم دقیق (fine tuning) نام دارد. یک شرکت فناوری ممکناست بخواهد چتباتی را برای پاسخگویی به سؤالات مختلف مشتریان و پشتیبانی فنی با سطوح مختلف جزئیات بسته به دانش کاربر تنظیم کند. یک شرکت حقوقی دیگر ممکناست یک مدل را برای تجزیه و تحلیل قراردادها تنظیم کند. یک تیم دیگر توسعه نیز ممکناست مدل را با کتابخانه کد گسترده خود و قراردادهای کدنویسی منحصر به فرد تنظیم کند. این مرحله نسبت به مرحله آموزش اولیه، به منابع محاسباتی کمتری نیاز دارد.
فرآیند تنظیم دقیق به تخصص و قدرت پردازشی بسیار کمتری نیاز دارد. طرفداران ترانسفورماتورها استدلال میکنند که هزینه بالای آموزش مدل های عمومی بزرگتر میتواند منجر به صرفهجویی در زمان و هزینه در سفارشیسازی مدل برای بسیاری از موارد استفاده مختلف باشد.
گاهی اوقات تعداد ویژگیها در یک مدل به جای معیارهای برجستهتر، به عنوان معیاری برای عملکرد آن استفاده میشود. با این حال، اندازه مدل لزوماً نشاندهنده عملکرد بهتر آن نیست. به عنوان مثال، گوگل اخیراً با استفاده از تکنیک ترکیبی از متخصصان (mixture-of-experts)، آزمایشهای کارآمدتری را برای آموزش LLM انجام داد که ثابت شد حدود هفت برابر کارآمدتر از مدل های دیگر میباشد. حتی اگر برخی از این مدل های حاصل بیش از یک تریلیون پارامتر داشتند، دقت آنها کمتر از مدل هایی با صدها برابر پارامتر کمتر بود.
با این حال، شرکت متا اخیراً گزارش داد که مدل زبانی بزرگ هوش مصنوعی متا (Llama) با 13 میلیارد پارامتر، در مقایسه با یک مدل ترنسفورمر از پیش آموزشداده شده مولد (GPT) با 175 میلیارد پارامتر، در معیارها و بنچمارکهای اصلی عملکرد بهتری داشتهاست. یک نوع 65 میلیارد پارامتری از Llama با عملکرد مدل هایی با بیش از 500 میلیارد پارامتر مطابقت داشت. این یافتهها نشان میدهد که اندازه مدل تنها عامل تعیینکننده عملکرد نیست و عوامل دیگری مانند معماری مدل و روشهای آموزش نیز بسیار مهم هستند.
دو نوآوری بزرگ در مدلهای ترانسفورماتور
مدلهای ترانسفورماتور دو نوآوری اساسی را معرفی کردهاند که به آنها امکان میدهد درک عمیقتری از زبان داشته باشند. این نوآوریها به ویژه در زمینه پیشبینی متن بسیار مؤثر واقع شدهاند. در ادامه به بررسی این دو نوآوری میپردازیم.
- رمزگذاری موقعیتی (Positional encoding): یکی از چالشهای اصلی در پردازش زبان طبیعی، حفظ ترتیب کلمات در یک جمله میباشد. زیرا تغییر ترتیب کلمات میتواند به طور کامل معنای جمله را تغییر دهد. برای حل این مشکل، مدلهای ترنسفورمر از روشی به نام “رمزگذاری موقعیتی” استفاده میکنند.
در این روش، به هر کلمه یا توکن در جمله یک عدد منحصر به فرد اختصاص داده می شود که نشاندهنده موقعیت آن کلمه و توکن (بخشهایی از ورودی مانند کلمات یا توکنها در NLP) در جمله است. این اعداد به مدل کمک میکنند تا اطلاعات مربوط به ترتیب توکنها را به خاطر بسپارد و درک کند که هر کلمه در چه جایگاهی از جمله قرار دارد. به عبارت دیگر، مدل با استفاده از این اعداد، میتواند ترتیب کلمات را درک کند و از این اطلاعات برای پیشبینی کلمات بعدی استفاده کند.
2. خودتوجهی (Self-attention): نوآوری دیگری که مدلهای ترانسفورماتور به همراه آوردهاند، “مکانیسم خودتوجهی” میباشد. این مکانیسم به مدل اجازه میدهد تا ارتباط بین کلمات مختلف در یک جمله را درک کند.
در واقع، مدل ترنسفورمر با استفاده از مکانیسم خودتوجهی، به هر کلمه یا توکن در جمله اجازه میدهد تا به سایر کلمات توجه کند و اهمیت آنها را برای خودش ارزیابی کند. به این ترتیب، مدل میتواند به طور همزمان به همه کلمات در جمله نگاه کند و ارتباط بین آنها را درک کند.
برای مثال، اگر جملهای به مدل داده شود، مدل میتواند با استفاده از مکانیسم خودتوجهی، تشخیص دهد که کدام کلمات به هم مرتبطتر هستند و کدام کلمات کمتر مرتبط هستند. این امر به مدل کمک میکند تا معنای کلی جمله را بهتر درک کند و پیشبینیهای دقیقتری انجام دهد.
مدل ترنسفومر چگونه کار میکند؟
مدلهای ترانسفورماتور با پردازش اطلاعات ورودی، مانند توالیهای توکنها یا دادههای ساختار یافته، کار میکنند. این مدلها از لایههای مختلفی تشکیل شدهاند که هر لایه دارای دو بخش اصلی است: مکانیسم خودتوجهی و شبکه عصبی پیشخور (FFN). مکانیسم خودتوجهی به مدل کمک میکند تا روابط بین اجزای مختلف داده ورودی را درک کند، در حالی که شبکه عصبی پیشخور پردازشهای پیچیدهتری را بر روی این اطلاعات انجام میدهد.
تصور کنید که نیاز دارید یک جمله انگلیسی را به فرانسوی تبدیل کنید. موارد زیر مراحل مورد نیاز برای انجام این کار با یک مدل ترنسفورمر هستند.
1. تعبیهی ورودی (Input embeddings):
برای اینکه یک مدل ترانسفورماتور بتواند روی متن کار کند، ابتدا باید کلمات و یا توکنها به شکلی تبدیل شوند که برای کامپیوتر قابل فهم باشد. این کار با استفاده از چیزی به نام “تعبیه” انجام می شود. در واقع، هر کلمه به یک مجموعه اعداد تبدیل میشود. این اعداد به نوعی نشاندهندهی معنای کلمه و ارتباط آن با سایر کلمات هستند.
این تعبیهها میتوانند به دو روش ایجاد شوند:
- تعبیههای یادگرفته شده: در این روش، مدل ترنسفورمر در حین آموزش، به طور خودکار تعبیههای مناسب برای هر کلمه را یاد میگیرد.
- تعبیههای از پیش آموزشدیده: در این روش، از تعبیههایی که قبلاً روی مجموعه دادههای بزرگ آموزش دیدهاند استفاده می شود. این تعبیهها حاوی اطلاعات معنایی غنی هستند و میتوانند به بهبود عملکرد مدل کمک کنند.

2. رمزگذاری موقعیتی (Positional encoding):
در مرحلهی قبلی، کلمات به اعداد تبدیل شدند، اما ما هنوز اطلاعاتی در مورد ترتیب کلمات در جمله نداریم. برای مثال، جملات “علی کتاب رضا را خواند” و “رضا کتاب علی را خواند” معنای متفاوتی دارند، اگرچه از کلمات یکسانی تشکیل شدهاند.
برای حل این مشکل، تکنیکی به نام “رمزگذاری موقعیتی” مورد استفاده قرار میگیرد. این رمزگذاری، اطلاعاتی در مورد موقعیت هر کلمه یا توکن در جمله را به تعبیههای آن اضافه میکند. به عبارت دیگر، به هر کلمه یا توکن یک برچسب عددی داده میشود که نشان میدهد این کلمه در کدام موقعیت از جمله قرار دارد.
این برچسبهای عددی به صورت خاص طراحی شدهاند تا به مدل ترانسفورماتور کمک کنند تا ترتیب کلمات را درک کند. این کار با استفاده از توابع ریاضی خاصی انجام می شود که الگوهای مشخصی را ایجاد میکنند. این الگوها به مدل اجازه میدهند تا فاصله بین کلمات و همچنین ترتیب آنها را درک کند.
3. توجه چندسر (Multi-head attention):
تا اینجای کار، فهمیدیم که مدل ترنسفورمر با تبدیل کلمات به اعداد و اضافه کردن اطلاعات موقعیتی، آماده پردازش جمله میشود. اما مدل چگونه متوجه می شود که کدام کلمات به هم مرتبط هستند؟ پاسخ این سوال در مکانیسمی به نام “توجه چندسر” نهفتهاست.
توجه چندسر مثل داشتن چندین جفت چشم میباشد که هر کدام به یک بخش از جمله نگاه میکنند. هر یک از این “سرهای توجه” به دنبال روابط خاصی بین کلمات و توکنها میگردند. مثلاً یک سر توجه ممکناست به دنبال کلماتی باشد که معنای مشابهی دارند، در حالی که سر توجه دیگری به دنبال کلماتی باشد که ارتباط نحوی با هم دارند.
برای اینکه مدل بداند به کدام کلمه باید بیشتر توجه کند، از تابعی به نام تابع بیشینه هموار (Softmax functions)، نوعی تابع فعالسازی، استفاده میشود. این تابع به مدل کمک میکند تا به هر کلمه وزنی اختصاص دهد. کلماتی که ارتباط بیشتری با کلمه مورد نظر دارند، وزن بیشتری دریافت میکنند.
4. نرمالسازی لایه و اتصالات باقیمانده (Layer normalization and residual connections):
تا اینجا با مکانیسمهای اصلی ترانسفورماتور آشنا شدیم. اما برای اینکه این مدل بتواند به خوبی آموزش ببیند و نتایج دقیقتری تولید کند، به برخی تکنیکهای اضافی نیاز داریم. دو تا از مهمترین این تکنیکها، نرمالسازی لایه و اتصالات باقیمانده هستند.
- نرمالسازی لایه: در یک مثال ساده برای درک مفهوم نرمالسازی، میتوان به یک مسابقه دو اشاره کرد. در این مسابقه، هر شرکتکننده مسافت متفاوتی را دویده است، به عنوان مثال یکی 100 متر، دیگری 200 متر و فردی دیگر 300 متر. برای مقایسه سرعتها، لازم است مسافتهای مختلف به یک مسافت ثابت، مثلاً 100 متر، تبدیل شوند. این فرآیند همان نرمالسازی میباشد، که در آن دادههای مختلف به شکلی تغییر داده میشوند تا مقایسه آنها ممکن گردد. در نهایت، با نرمالسازی، سرعت شرکتکنندگان بر اساس مسافت یکسان قابل مقایسه خواهد بود. این روش در بسیاری از مسائل علمی و محاسباتی به کار میرود تا اعداد و دادههای متفاوت قابل مقایسه شوند. نرمالسازی لایه نیز کاری مشابه انجام میدهد. این تکنیک، مقادیر خروجی هر لایه را به یک محدوده مشخص تبدیل میکند تا آموزش مدل با سرعت و پایداری بیشتری انجام شود.
- اتصالات باقیمانده: در این روش، خروجی هر لایه به ورودی لایه بعدی اضافه میشود. این کار باعث می شود که مدل بتواند اطلاعات را بهتر حفظ کند و از مشکلاتی مانند ناپدید شدن گرادیان جلوگیری کند. ناپدید شدن گرادیان مشکلی است که در شبکههای عصبی عمیق رخ میدهد و باعث میشود که لایههای اولیه به خوبی آموزش نبینند.
5. شبکههای عصبی پیشخور (Feedforward neural networks):
پس از آنکه مکانیسم توجه چندسر، ارتباط بین کلمات را مشخص کرد، اطلاعات به لایههای دیگری به نام “شبکههای عصبی پیشخور” ارسال می شود. این شبکهها وظیفه دارند تا الگوهای پیچیدهتری را در دادهها کشف کنند.
تصور کنید که شبکههای عصبی پیشخور مانند یک کارخانه پردازش اطلاعات هستند. این کارخانه، مواد خام (یعنی اطلاعاتی که از مکانیسم توجه دریافت کردهاست) را به محصول نهایی (یعنی یک نمایش پیچیده از جمله) تبدیل میکند. در این کارخانه، عملیات مختلفی روی دادهها انجام میشود که به آنها “تبدیلات غیرخطی” میگویند. این تبدیلات به مدل اجازه میدهند تا روابط بسیار پیچیدهای را بین کلمات پیدا کند. همچنین این مرحله هوش مصنوعی جعبه سیاه نیز نامیده میشود.
6. لایههای انباشته (Stacked layers):
تا اینجا با اجزای اصلی یک بلوک ترنسفورمر آشنا شدیم. اما یک ترانسفورماتور کامل از چندین بلوک به هم متصل شدهاست که به آنها “لایههای انباشته” گفته می شود. تصور کنید که میخواهیم یک تصویر را توصیف کنیم. ابتدا جزئیات کوچک تصویر را بررسی میکنیم. سپس این جزئیات را با هم ترکیب میکنیم تا اجزای بزرگتر تصویر را تشکیل دهیم. در نهایت، با ترکیب این اجزای بزرگتر، توصیف کلی تصویر را ارائه میدهیم. (در پردازش تصویر یک گربه، مدل ابتدا کوچکترین جزئیات عکس را به صورت پیکسل به پیکسل بررسی میکند، سپس در مراحل بعد با بررسی اجزای بزرگتر، متوجه میشود که عکس، متعلق به تصویر یک گربه میباشد).
لایههای انباشته در ترانسفورماتور نیز به همین شکل عمل میکنند. هر لایه، اطلاعاتی که از لایه قبلی دریافت میکند را پردازش میکند و آن را به اطلاعاتی پیچیدهتر و انتزاعیتر تبدیل میکند. لایه اول، الگوهای سادهای مانند کلمات و روابط مستقیم بین آنها را تشخیص میدهد. لایههای بعدی، این الگوها را با هم ترکیب میکنند تا الگوهای پیچیدهتر و معناییتری را شناسایی کنند.
با افزایش تعداد لایهها، مدل ترنسفورمر قادر میباشد تا ویژگیهای بسیار پیچیده و انتزاعی در دادهها را درک کند. به همین دلیل است که ترانسفورماتورها در بسیاری از وظایف پردازش زبان طبیعی، مانند ترجمه ماشینی و تولید متن، عملکرد بسیار خوبی دارند.
7. لایه خروجی (Output layer):
تا به این مرحله، مدل ترانسفورماتور ورودی را پردازش کرده و نمایشهای پیچیدهای از آن ایجاد کردهاست. اما هدف نهایی، تولید یک خروجی معنادار میباشد. برای مثال، در ترجمه ماشینی، ورودی یک جمله به زبان مبدا است و خروجی، همان جمله ترجمه شده به زبان مقصد میباشد.
برای تولید خروجی، از یک بخش جداگانه به نام “لایه رمزگشا” استفاده میشود. این لایه، نمایشهای ایجاد شده توسط لایههای انباشته را به عنوان ورودی دریافت میکند و با استفاده از مکانیسمهای مشابهی که در بخش رمزگذار استفاده شدهاست، یک دنباله از کلمات را به عنوان خروجی تولید میکند.
به عبارت سادهتر، لایه رمزگشا، اطلاعاتی که مدل در مورد ورودی به دست آوردهاست را به شکلی قابل فهم برای انسان تبدیل میکند. این لایه، کلمه به کلمه خروجی را پیشبینی میکند و در هر مرحله، از کلماتی که قبلاً تولید شدهاست به عنوان ورودی برای پیشبینی کلمه بعدی استفاده میکند.
8. آموزش (Training):
تا به این مرحله، سوال اصلی که مطرح می شود این است که چگونه این مدل میتواند وظایفی مانند ترجمه یا تولید متن را انجام دهد؟ پاسخ این سوال در فرایند آموزش نهفتهاست.
آموزش مدل ترنسفورمر به این صورت میباشد که به آن مثالهای بسیار زیادی از دادههای ورودی و خروجی داده میشود. برای مثال، در ترجمه ماشینی، به مدل جملاتی به زبان مبدا و ترجمه صحیح آنها به زبان مقصد داده می شود.
مدل ترانسفورماتور تلاش میکند تا الگوهایی را در این دادهها پیدا کند و بتواند خروجیهای صحیح را برای ورودیهای جدید تولید کند. برای این کار، از یک تابع ریاضی به نام “تابع زیان (loss function)” استفاده میشود. این تابع، تفاوت بین خروجیای که مدل تولید میکند و خروجی صحیح را محاسبه میکند. هدف آموزش، پیدا کردن پارامترهایی برای مدل است که باعث شود مقدار این تابع زیان به حداقل برسد.
برای به حداقل رساندن تابع زیان، از روشهای بهینهسازی مانند “نزول گرادیان تصادفی (SGD)” و یا روش Adam استفاده می شود. این روش به مدل اجازه میدهد تا به تدریج پارامترهای خود را تنظیم کند و به پاسخ صحیح نزدیکتر شود.
9. استنتاج (Inference):
پس از آنکه مدل ترنسفورمر به طور کامل آموزش دید و پارامترهای آن تنظیم شد، آمادهاست تا برای انجام وظایف مختلف مورد استفاده قرار گیرد. این مرحله را “استنتاج” مینامیم.
در مرحله استنتاج، یک دنباله جدید (مثلاً یک جمله یا یک متن) به عنوان ورودی به مدل داده میشود. مدل، این ورودی را از لایههای مختلف خود عبور میدهد و در نهایت یک خروجی تولید میکند. این خروجی میتواند یک ترجمه، یک متن تولید شده، یا هر خروجی دیگری باشد که مدل برای آن آموزش دیدهاست.
برای مثال، اگر مدل برای ترجمه متن آموزش دیده باشد، در مرحله استنتاج، یک جمله به زبان مبدا به آن داده می شود و مدل جمله ترجمه شده به زبان مقصد را تولید میکند. یا اگر مدل برای تولید متن آموزش دیده باشد، در مرحله استنتاج، به آن چند کلمه اولیه داده میشود و مدل بقیه متن را تکمیل میکند.
کاربردهای مدل ترانسفورماتور
مدلهای ترنسفورمر به عنوان ابزارهای قدرتمندی برای پردازش انواع مختلف دادهها در طیف وسیعی از کاربردها مطرح شدهاند. این مدلها قادرند ورودیهای متنوعی را دریافت کرده و خروجیهای متناسب با آن تولید کنند. از جمله کاربردهای گسترده ترانسفورماتورها میتوان به موارد زیر اشاره کرد:
- ترجمه ماشینی: تبدیل متون از یک زبان به زبان دیگر با حفظ معنای اصلی.
- توسعه چتبات: ایجاد چتباتهایی که قادر به مکالمات طبیعی و مفید با کاربران باشند.
- خلاصهسازی متن: استخراج اطلاعات کلیدی از متون طولانی و ارائه خلاصهای دقیق و مفید.
- تولید محتوا: ایجاد متون جدید بر اساس درخواستهای کوتاه و مشخص.
- طراحی دارو: طراحی ساختارهای شیمیایی داروهای جدید با توجه به خواص مورد نظر.
- تولید تصاویر: تولید تصاویر واقعگرایانه یا هنری بر اساس توصیفات متنی.
- توصیف تصاویر: تولید توصیفات متنی دقیق برای تصاویر.
- خودکارسازی فرآیندها: ایجاد اسکریپتهای خودکار برای انجام وظایف تکراری.
- تکمیل کد: ارائه پیشنهادات برای تکمیل کدهای برنامهنویسی به صورت خودکار.
پیاده سازی مدلهای ترنسفومر
مدلهای ترانسفورماتور به سرعت در حال تکامل و گسترش کاربردهای خود هستند. این مدلها در حوزههای مختلفی از جمله پردازش زبان طبیعی، تولید محتوا، تصویرسازی، تحلیل دادههای پزشکی و حتی کشف دارو به کار گرفته میشوند. برخی از برجستهترین پیادهسازیهای ترنسفورمر شامل موارد زیر میباشد:
- BERT (Bidirectional Encoder Representations from Transformers): یکی از اولین مدل های بزرگ زبانی مبتنی بر ترانسفورماتور میباشد که توسط گوگل توسعه یافتهاست.
- GPT (Generative Pre-trained Transformer): سری مدلهای زبانی بزرگ تولید شده توسط شرکت OpenAI که در زمینه تولید متن و گفتگو بسیار قدرتمند هستند از جمله GPT-2، GPT-3، GPT-3.5، GPT-4، GPT-4o، GPT-4o mini و OpenAI o1
- Llama: مدلی مشابه GPT است که توسط شرکت متا توسعه یافته و عملکرد قابل مقایسهای با مدل های بزرگتر دارد.
- Pathways Language Model: مدلی چند وجهی از گوگل که قادر به انجام وظایف مختلفی در حوزههای متن، تصویر و کنترل رباتیک است.
- Dall-E: مدلی از OpenAI که میتواند تصاویر واقعگرایانه یا هنری را بر اساس توصیفات متنی تولید کند.
- GatorTron: مدلی مشترک بین دانشگاه فلوریدا و انویدیا که برای تحلیل دادههای پزشکی بدون ساختار استفاده می شود.
- AlphaFold 2: مدلی از DeepMind که قادر به پیشبینی ساختار سه بعدی پروتئینها میباشد.
- MegaMolBART: مدلی مشترک بین آسترازنکا و انویدیا که برای کشف داروهای جدید و تولید ساختارهای شیمیایی مورد استفاده قرار میگیرد.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





