در مقالهی پیشین هامیا ژورنال به توضیح کلی و معرفی انواع مدلهای یادگیری ماشین پرداختیم. در این مقاله تمرکز ویژهای بر روی یکی از این مدلها یعنی “یادگیری با نظارت” خواهیم داشت. یادگیری با نظارت رویکردی برای ایجاد هوش مصنوعی (AI) است که در آن یک الگوریتم کامپیوتری روی دادههای ورودی که برای یک خروجی خاص برچسبگذاری شدهاند، آموزش میبیند. مدل تا زمانی آموزش داده میشود که بتواند الگوها و روابط زمینهای بین دادههای ورودی و برچسبهای خروجی را شناسایی کند و این امکان را به آن میدهد تا در مواجه با دادههای کاملاً جدید، نتایج برچسبگذاری دقیقی ارائه دهد. هدف در یادگیری نظارت شده، درک دادهها در چارچوب یک سوال خاص میباشد. یادگیری تحت نظارت در حل مسائل طبقه بندی و رگرسیون عملکرد خوبی دارد، مانند تعیین اینکه یک مقاله خبری به کدام دسته بندی تعلق دارد یا پیش بینی حجم فروش برای یک تاریخ آینده مشخص. سازمانها میتوانند از یادگیری با ناظر در فرآیندهایی مانند تشخیص ناهنجاری، تشخیص تقلب، طبقه بندی تصویر، ارزیابی ریسک و فیلتر کردن ایمیلهای spam استفاده کنند.
در مقابل یادگیری با ناظر، یادگیری ماشین بدون نظارت قرار دارد. در این رویکرد، الگوریتم با دادههای بدون برچسب ارائه میشود و به گونهای طراحی شدهاست که به طور مستقل الگوها یا شباهتها را کشف کند. این فرآیند در ادامه با جزئیات بیشتر توضیح داده خواهد شد.
یادگیری با نظارت چگونه کار میکند؟
مانند تمام الگوریتمهای یادگیری ماشین، یادگیری با ناظر بر اساس آموزش استوار میباشد. در طول مرحله آموزش، مجموعه دادههای برچسبگذاری شدهای به سیستم داده میشود که به سیستم آموزش میدهد خروجی مربوط به هر مقدار ورودی خاص چیست. سپس مدل آموزش دیده با دادههای آزمون (آزمایش) مواجه میشود. اینها دادههایی هستند که برچسبگذاری شدهاند، اما برچسبها به الگوریتم نشان داده نشدهاست. هدف از دادههای آزمون، اندازهگیری میزان دقت عملکرد الگوریتم روی دادههای برچسبگذاری نشدهاست.
مراحل اساسی عمومی در اجرای یادگیری نظارت شده عبارتند از:
- نوع دادههای آموزشی را که به عنوان مجموعه آموزشی استفاده میشود، تعیین کنید.
- دادههای آموزشی برچسب گذاری شده را جمع آوری کنید.
- دادههای آموزشی را به مجموعه دادههای آموزشی، آزمایشی و اعتبارسنجی تقسیم کنید.
- الگوریتمی را برای استفاده در مدل یادگیری ماشین تعیین کنید.
- الگوریتم را با مجموعه دادههای آموزشی اجرا کنید.
- دقت مدل را ارزیابی کنید. اگر مدل خروجیهای درستی را پیشبینی کند، پس دقیق بالایی دارد.
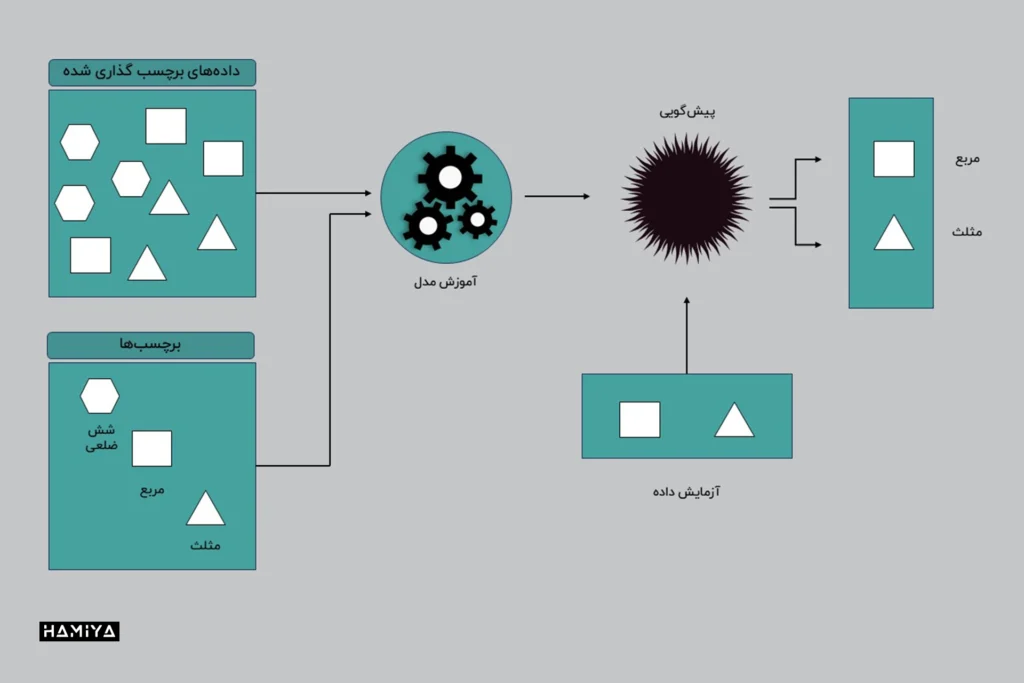
به عنوان مثال، یک الگوریتم را میتوان با تغذیه حجم زیادی از دادههای آموزشی که شامل تصاویر برچسبگذاری شدهی مختلف گربه و سگ است، برای شناسایی تصاویر گربه و سگ آموزش داد. این دادههای آموزشی زیرمجموعهای از عکسها از یک مجموعه داده بسیار بزرگتر از تصاویر خواهد بود. پس از آموزش، مدل باید بتواند پیشبینی کند که خروجی یک تصویر، یک گربه یا یک سگ است. برای اعتبارسنجی مدل، میتوان مجموعه دیگری از تصاویر را از الگوریتم عبور داد.
در الگوریتمهای شبکه عصبی، فرآیند یادگیری با نظارت با اندازهگیری مداوم خروجیهای مدل و تنظیم دقیق سیستم برای نزدیکتر شدن به دقت هدف، بهبود مییابد. میزان دقتی که به دست میآید به دو عامل بستگی دارد: دادههای برچسبگذاری شده در دسترس و الگوریتمی که استفاده میشود. علاوه بر این، عوامل زیر بر این فرآیند تأثیر میگذارند:
- دادههای آموزشی باید متوازن و پاکسازی شده باشند. دادههای نامعتبر یا تکراری درک هوش مصنوعی را منحرف میکنند؛ بنابراین، دانشمندان داده باید نسبت به دادههایی که مدل با آنها آموزش میبیند، دقت کافی داشته باشند.
- تنوع دادهها عملکرد هوش مصنوعی را در مواجه با موارد جدید تعیین میکند. اگر نمونههای کافی در مجموعه دادههای آموزشی وجود نداشته باشد، مدل با مشکل مواجه شده و در ارائه پاسخهای قابل اعتماد شکست میخورد.
- دقت بالا، به طور متناقضی، لزوماً نشانگر خوبی نیست. این همچنین میتواند به معنای بیش برازش (Overfitting) مدل باشد، به این معنی که بیش از حد روی مجموعه داده آموزشی خاص خود تنظیم شده است. چنین مجموعه دادهای ممکن است در سناریوهای آزمایشی عملکرد خوبی داشته باشد، اما در مواجه با چالشهای دنیای واقعی به طرز ناامیدکنندهای شکست بخورد. برای جلوگیری از بیش برازش، مهم است که دادههای آزمون با دادههای آموزشی متفاوت باشند تا اطمینان حاصل شود که مدل پاسخها را از تجربه قبلی خود نمیگیرد، بلکه استنتاج مدل تعمیم داده شده (generalized) است.
- از طرف دیگر، الگوریتم چگونگی استفاده از آن داده را تعیین میکند. برای مثال، الگوریتمهای یادگیری عمیق را میتوان برای استخراج میلیاردها پارامتر از دادههایشان آموزش داد و به سطوح بیسابقهای از دقت دست یافت، همانطور که توسط GPT-3 شرکت OpenAI نشان داده شده است.
معرفی ChatGPT | انقلابی بزرگ در هوش مصنوعی
به غیر از شبکههای عصبی، بسیاری از الگوریتمهای یادگیری تحت نظارت دیگری نیز وجود دارد. الگوریتمهای یادگیری با نظارت عمدتاً دو نوع خروجی تولید میکنند: طبقهبندی و رگرسیون.
الگوریتمهای طبقه بندی یادگیری با ناظر
الگوریتمهای یادگیری نظارت شده به دو نوع طبقه بندی و رگرسیون تقسیم میشوند.
یک الگوریتم طبقه بندی با تکیه بر دادههای برچسب گذاری شده ای که آموزش دیدهاست، دادههای ورودی را به تعداد مشخصی از دستهها (کلاسها) مرتب میکند. الگوریتمهای طبقهبندی میتوانند برای طبقهبندیهای دودویی، مانند طبقهبندی یک تصویر به عنوان سگ یا گربه، فیلتر کردن ایمیل به اسپم یا غیر اسپم و دستهبندی بازخورد مشتری به مثبت یا منفی استفاده شوند.
نمونههایی از تکنیکهای یادگیری ماشین طبقهبندی شامل موارد زیر است:
- یک درخت تصمیم (decision tree)، نقاط داده را از تنه درخت به شاخهها و سپس برگها جدا میکند و دستههای کوچکتری را درون دستههای دیگر ایجاد میکند. به عبارت دیگر، درخت تصمیم دادهها را بر اساس ویژگیهایشان به صورت سلسله مراتبی طبقهبندی میکند.
- رگرسیون لجستیک (Logistic regression) متغیرهای مستقل را برای تعیین یک نتیجه باینری که در یکی از دو دسته قرار میگیرد، تجزیه و تحلیل میکند.
- جنگل تصادفی (random forest) مجموعهای از درختان تصمیم است که نتایج را از پیشبینیکنندههای مختلف جمعآوری میکند. این روش در تعمیمپذیری (generalization) بهتر عمل میکند، اما در مقایسه با درختان تصمیم، قابلیت تفسیر آن (interpretable) کمتر است.
- در الگوریتم ماشین بردار پشتیبان (Support Vector Machine – SVM) طی فرایند آموزش مدل، خطی پیدا میشود که دادهها را در یک مجموعه دادهی مشخص به دستههای (کلاس) خاصی تقسیم کند و همزمان حاشیهی هر دسته را به حداکثر برساند. از این الگوریتمها میتوان برای مقایسهی عملکرد مالی نسبی، ارزش سهام و سود سرمایهگذاری استفاده کرد.
مدلهای رگرسیون در یادگیری نظارت شده
وظایف رگرسیون (Regression Tasks) با وظایف طبقه بندی متفاوت هستند، زیرا در رگرسیون انتظار میرود مدل یک رابطه عددی بین دادههای ورودی و خروجی ایجاد کند. نمونههایی از مدلهای رگرسیون عبارتند از:
- پیش بینی قیمت املاک و مستغلات بر اساس کدپستی (ZIP code): در این مثال، مدل رگرسیون با در نظر گرفتن کدپستی به عنوان ورودی، خروجی را که قیمت تخمینی املاک است، به صورت عددی پیش بینی میکند.
- پیش بینی نرخ کلیک در تبلیغات آنلاین با توجه به زمان روز: اینجا مدل رگرسیون زمان روز را به عنوان ورودی در نظر میگیرد و خروجی را که نرخ کلیک تخمینی تبلیغات است، به صورت عددی پیش بینی میکند.
- تعیین میزان تمایل مشتریان به پرداخت برای یک محصول خاص بر اساس سن: در این سناریو، مدل رگرسیون سن مشتری را به عنوان ورودی دریافت میکند و خروجی، یعنی حداکثر قیمتی که مشتری حاضر به پرداخت برای محصول است، را به صورت عددی پیش بینی میکند.
الگوریتمهایی که معمولاً در برنامههای یادگیری تحت نظارت استفاده میشوند شامل موارد زیر است:
- منطق بیزی (Bayesian logic) به تحلیل مدلهای آماری میپردازد، در حالی که دانش قبلی در مورد پارامترهای مدل یا خود مدل را نیز در نظر میگیرد.
- رگرسیون خطی (linear Regression) یک مقدار متغیر را بر اساس مقدار متغیر دیگر پیش بینی میکند.
- رگرسیون غیرخطی (Nonlinear Regression) زمانی استفاده میشود که خروجی قابل بازتولید از ورودیهای خطی نباشد. در این حالت، نقاط داده یک رابطه غیرخطی دارند، به عنوان مثال، دادهها ممکن است یک روند غیرخطی و منحنی داشته باشند.
- درخت رگرسیون (regression tree) نوعی درخت تصمیم است که در آن میتوان مقادیر پیوسته را از متغیر هدف دریافت کرد.
ملاحظات کلیدی هنگام انتخاب الگوریتم یادگیری تحت نظارت
هنگام انتخاب یک الگوریتم یادگیری نظارت شده، به چند نکته باید توجه کرد:
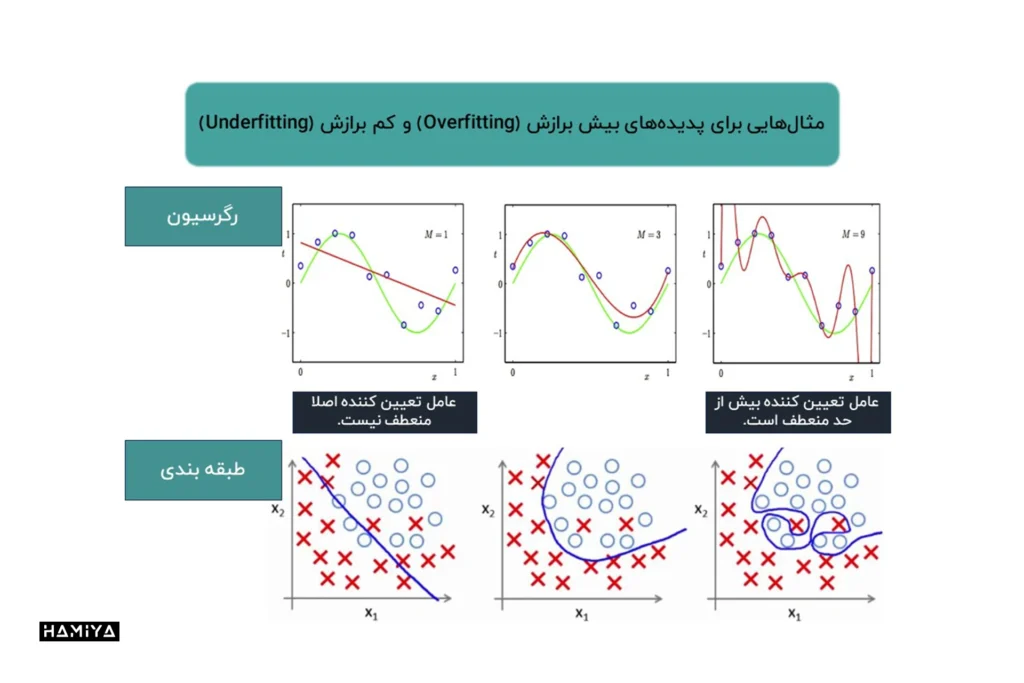
- سوگیری و واریانس (Bias-Variance): در الگوریتم، بین انعطافپذیری کافی و بیش از حد انعطافپذیر بودن، یک خط باریک وجود دارد. الگوریتم باید بتواند تعادلی بین کمبرازش (Underfitting) و بیشبرازش (Overfitting) دادهها برقرار کند.
- پیچیدگی مدل (Model Complexity): پیچیدگی مدلی که سیستم سعی در یادگیری آن دارد، باید در نظر گرفته شود. به طور کلی، مدلهای سادهتر به دلیل قابلیت تفسیر بهتر، ترجیح داده میشوند.
- تحلیل دادهها (Data Analysis): قبل از انتخاب الگوریتم، دادهها باید از نظر ناهمگنی (Heterogeneity)، دقت (Accuracy)، همبستگی (Redundancy) و خطی بودن (Linearity) مورد تجزیه و تحلیل قرار گیرند.
- واریانس (Variance): تمایل الگوریتم است که الگوهای بسیار خاص را از دادههای آموزشی یاد بگیرد که در مورد دادههای جدید عملکرد خوبی نداشته باشد.
- کمبرازش (Underfitting): زمانی اتفاق میافتد که مدل الگوهای کافی از دادهها را یاد نگرفته باشد.
- بیشبرازش (Overfitting): زمانی رخ میدهد که مدل الگوهای خاص دادههای آموزشی را بیش از حد یاد گرفته باشد و نتواند بر روی دادههای جدید به خوبی عمل کند.
- ناهمگنی (Heterogeneity): نشاندهندهی میزان تنوع و توزیع مقادیر در یک مجموعه داده است.
- همبستگی (Redundancy): وجود ویژگیهای تکراری یا مرتبط در یک مجموعه داده است.
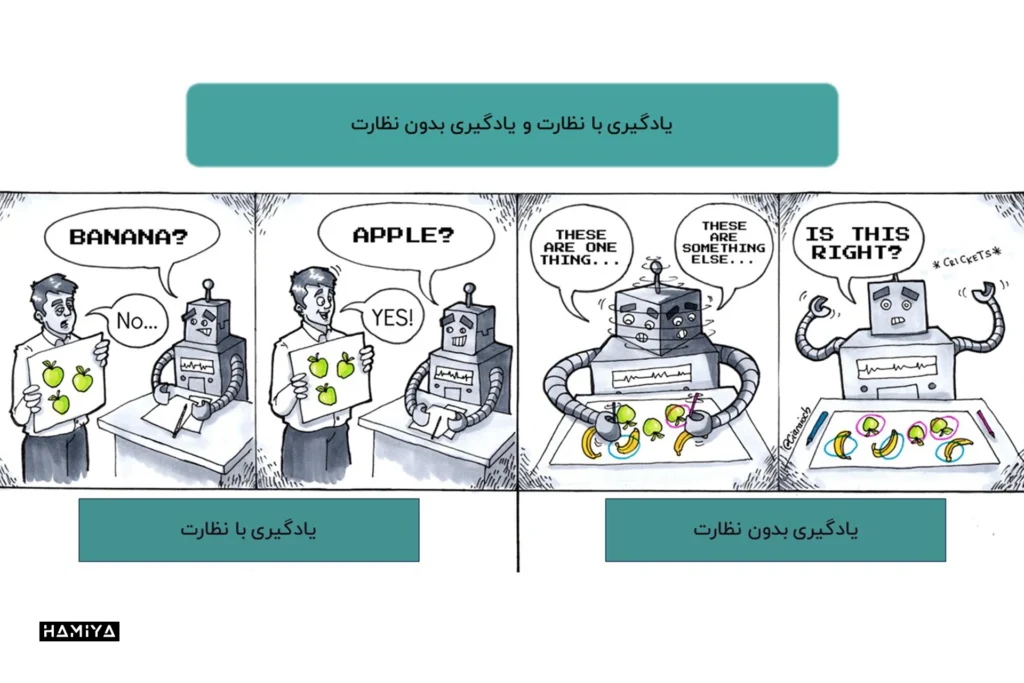
یادگیری تحت نظارت در مقابل یادگیری بدون نظارت
تفاوت اصلی بین یادگیری بدون نظارت و تحت نظارت، در نحوه یادگیری الگوریتم است.
یادگیری بدون نظارت رویکردی متفاوت نسبت به یادگیری با نظارت است. در یادگیری بدون نظارت، الگوریتم با دادههای بدون برچسب به عنوان مجموعه آموزشی تغذیه میشود. بر خلاف یادگیری با ناظر، در این روش خروجیهای صحیحی وجود ندارد. در عوض، الگوریتم الگوها و شباهتهای درون دادهها را کشف میکند، نه اینکه آنها را به یک معیار خارجی مرتبط سازد. به عبارت دیگر، الگوریتمها میتوانند به طور مستقل برای یادگیری بیشتر در مورد دادهها عمل کنند و یافتههای جالب یا غیرمنتظرهای را کشف کنند که انسانها به دنبال آنها نبودند.
یادگیری بدون نظارت در دو حوزهی اصلی کاربرد دارد:
- الگوریتمهای خوشه بندی (Clustering Algorithms): این الگوریتمها به کشف گروهها (یا خوشهها) درون دادهها میپردازند. به عبارتی دیگر، الگوریتمهای خوشه بندی دادهها را بر اساس شباهتهایشان سازماندهی میکنند.
- قوانین وابستگی (Association Rules)1: این مفهوم به پیشبینی قواعدی که دادهها را توصیف میکنند، اشاره دارد. با استفاده از الگوریتمهای یادگیری بدون نظارت، میتوان روابط و الگوهای پنهان بین ویژگیهای مختلف داده را کشف کرد.
بدلیل اینکه مدل یادگیری ماشین به تنهایی برای کشف الگوها در دادهها کار میکند، این مدل ممکن است طبقهبندیهای مشابه با یادگیری نظارتشده را انجام ندهد. در مثال سگها و گربهها، مدل یادگیری بدون نظارت ممکن است تفاوتها، شباهتها و الگوهای بین سگ و گربه را مشخص کند، اما نمیتواند آنها را به عنوان سگ یا گربه برچسبگذاری کند.
مزایا و محدودیتهای مدلهای یادگیری تحت نظارت
مدلهای یادگیری نظارت شده نسبت به رویکرد بدون نظارت مزایایی دارند، اما در عین حال محدودیتهایی نیز دارند. مزایا و محدودیتهای مدلهای یادگیری تحت نظارت، مطابق با جدول زیر است:
مزایای مدلهای یادگیری تحت نظارت
✅ سیستمهای یادگیری نظارت شده قضاوتهایی را انجام میدهند که انسانها میتوانند با آنها ارتباط برقرار کنند، زیرا این انسانها هستند که مبنای تصمیمگیری را فراهم میکنند.
✅ در مدلهای یادگیری با نظارت، معیارهای عملکرد به دلیل کمک اضافی افراد باتجربه بهینه شده است.
✅ وظایف مربوط به طبقه بندی و رگرسیون در مدلهای یادگیری نظارت شده انجام میگیرد.
✅ مدلهای با ناظر، میتوانند براساس تجربیات قبلی پیشبینیهایی را انجام دهند.
✅ در مدلهای یادگیری تحت نظارت، کاربران تعداد کلاسهای استفاده شده در دادههای آموزشی را کنترل میکنند.
محدودیتهای مدلهای یادگیری تحت نظارت
❌ در مورد روش مبتنی بر بازیابی، سیستمهای یادگیری نظارت شده در برخورد با اطلاعات جدید با مشکل مواجه میشوند. اگر سیستمی با دستهبندی برای سگ و گربه با دادههای جدیدی مانند یک گورخر مواجه شود، مجبور است آن را به اشتباه در یکی از دستههای دیگر قرار دهد. با این حال، اگر سیستم، هوش مصنوعی مولد باشد (بدون نظارت) ممکن است نداند که گورخر چیست، اما میتواند آن را به عنوان متعلق به یک دسته جداگانه تشخیص دهد.
❌ به طور معمول، یادگیری نظارت شده برای دستیابی به سطوح عملکرد قابل قبول، به مقادیر زیادی داده برچسبگذاری شدهی صحیح نیاز دارد و چنین دادههایی همیشه در دسترس نیستند. این گونه موارد برای یادگیری بدون نظارت به عنوان مشکل تلقی نمیشود و میتواند با دادههای برچسبگذاری نشده نیز کار کند.
❌ مدلهای تحت نظارت قبل از استفاده، به زمان نیاز دارند تا آموزش ببینند.
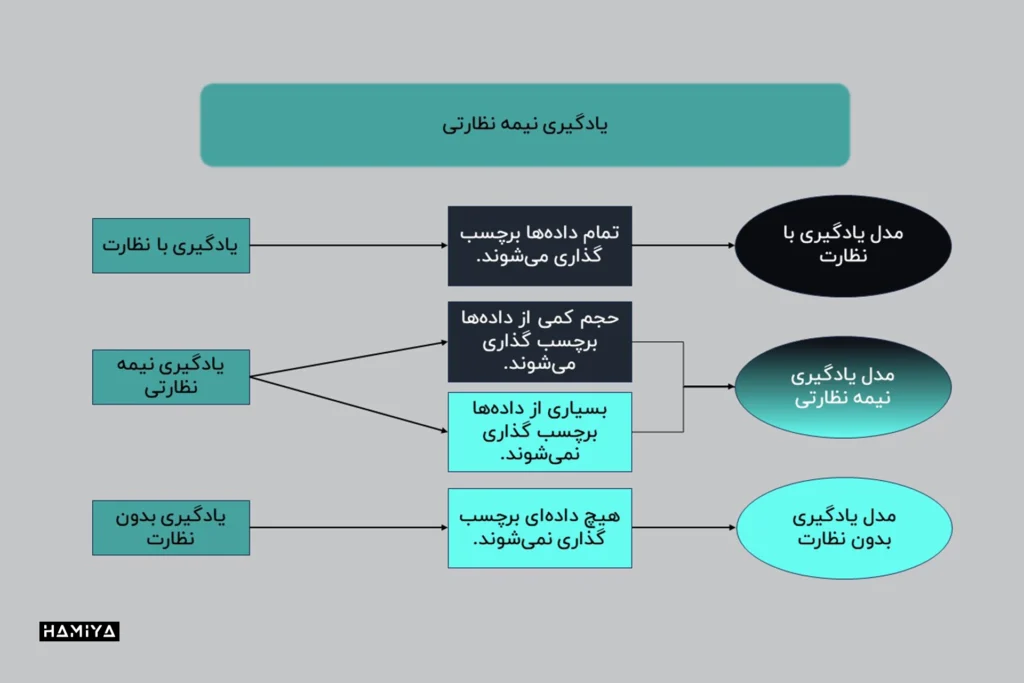
یادگیری نیمه نظارتی (Semi-supervised learning)
در مواردی که یادگیری نظارت شده مورد نیاز است، اما کمبود دادهی باکیفیت وجود دارد، یادگیری نیمه نظارت شده ممکن است روش یادگیری مناسب باشد. این مدل یادگیری بین یادگیری نظارت شده و بدون نظارت قرار میگیرد و دادههایی را میپذیرد که بخشی از آنها برچسبگذاری شدهاند، به این معنی که اکثر دادهها فاقد برچسب هستند.
یادگیری نیمه نظارت شده مشابه یادگیری بدون نظارت، همبستگی بین نقاط داده را تعیین میکند و سپس از دادههای برچسب گذاری شده برای علامتگذاری آن نقاط داده استفاده میکند. در نهایت، کل مدل بر اساس برچسبهای اعمالشده جدید آموزش میبیند.
یادگیری نیمه نظارت شده میتواند نتایج دقیقی را ارائه دهد و در بسیاری از مسائل دنیای واقعی قابل اجراست، جایی که مقدار کمی از دادههای برچسب گذاری شده مانع از عملکرد صحیح الگوریتمهای یادگیری نظارت شده میشود. به عنوان یک قاعده کلی، مجموعه دادهای با حداقل 25 درصد دادههای برچسب گذاری شده برای یادگیری نیمه نظارت شده مناسب است.
تشخیص چهره، برای مثال، برای یادگیری نیمه نظارت شده ایدهآل میباشد. تعداد زیادی از تصاویر افراد مختلف بر اساس شباهت خوشهبندی میشوند و سپس با یک تصویر برچسب گذاری شده معنا پیدا میکنند و به عکسهای خوشهبندیشده، هویت میدهند.
مروری بر فناوری دیپ فیک، کاربردها و روشهای شناسایی آن
نمونهای از یک پروژه آموزشی با نظارت
یک مورد استفادهی احتمالی از یادگیری نظارت شده، دستهبندی اخبار است. یک رویکرد این است که مشخص شود هر قطعه از خبر به کدام دسته تعلق دارد، مانند تجارت، امور مالی، فناوری یا ورزش. برای حل این مشکل، یک مدل یادگیری تحت نظارت بهترین گزینه خواهد بود.
با ارائهی مقالات خبری گوناگون همراه با دستهبندی آنها توسط انسانها، مدل یاد میگیرد که چه نوع خبری به هر دسته تعلق دارد. به این ترتیب، مدل بر اساس تجربهی آموزشی پیشین خود، قادر به تشخیص دستهی هر مقالهی خبری جدیدی که با آن مواجه میشود، خواهد بود.
با این حال، انسانها همچنین ممکن است به این نتیجه برسند که دستهبندی اخبار بر اساس طبقهبندیهای از پیش تعیینشده، بهاندازهی کافی کارآمد نیست. چرا که برخی از اخبار ممکن است دربارهی فناوریهای مقابله با تغییرات اقلیمی یا مشکلات نیروی کار در یک صنعت خاص صحبت کنند. میلیاردها مقاله خبری وجود دارد و تقسیم آنها به 40 یا 50 دسته ممکن است یک سادهسازی بیش از حد باشد.
به عنوان جایگزین، رویکرد بهتر میتواند یافتن شباهتها میان مقالات خبری و گروهبندی اخبار بر اساس آن شباهتها باشد. در این روش، به جای دستهبندی، به خوشههای خبری (news clusters) نگاه میکنیم. در خوشهبندی خبری، مقالات مشابه با هم، هم گروه میشوند و دیگر خبری از دستههای خاص (مانند سیاست، ورزش، سرگرمی) نیست.
این همان چیزی است که یادگیری بدون نظارت با تعیین الگوها و شباهتها درون دادهها به دست میآورد، برخلاف روشی که دادهها را به معیار خارجی خاصی مرتبط میکند.
- در هر تراکنش معینی با آیتمهای مختلف، قوانین وابستگی برای کشف قوانینی است که تعیین میکنند چگونه یا چرا اقلام خاص به هم متصل میشوند. ↩︎
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️