
از گذشتههای دور، انسانها زبانهای گفتاری را برای ارتباط با یکدیگر ابداع کردند. زبان، پایه و اساس همه شکلهای ارتباطی انسانی و فناوری است. واژهها، معانی و قواعد دستوری زبان، امکان انتقال ایدهها و مفاهیم را فراهم میکنند. در دنیای هوش مصنوعی نیز، مدلهای زبانی هدف مشابهی را دنبال میکنند و زیربنایی برای برقراری ارتباط و خلق مفاهیم تازه فراهم میآورند. این مدلها در واقع شبیه زبانهای انسانی عمل میکنند، اما به جای انسان، توسط ماشینها و کامپیوترها مورد استفاده قرار میگیرند.
فهرست مطالب
مدلهای زبانی بزرگ چیست؟
مدلهای زبانی بزرگ (LLM: Large Language Models) نوعی الگوریتم هوش مصنوعی هستند که میتوانند متون طولانی و پیچیده را درک کرده و براساس آنچه آموختهاند، متون جدید تولید کنند. این مدلها با استفاده از تکنیکهای یادگیری عمیق (Deep Learning) و دادههای زبانی بسیار زیاد آموزش دیدهاند تا الگوهای زبانی را بشناسند و بتوانند متون مشابه با آنچه آموختهاند تولید کنند. این فناوری بخشی از هوش مصنوعی مولد (Generative AI) است که به طور خاص برای تولید محتوای متنی طراحی شده است.
اولین نمونههای مدلهای زبانی هوش مصنوعی به دهه 1960 و اوایل پیدایش هوش مصنوعی بر میگردد. یکی از معروفترین آنها، مدل الایزا بود که در سال 1966 در دانشگاه MIT معرفی شد. در ابتدا، همه مدلهای زبانی روی مجموعهای از دادهها آموزش داده میشوند. سپس با استفاده از روشهای مختلف، روابط میان دادهها را درک میکنند تا بتوانند محتوای جدیدی شبیه به آنچه آموختهاند تولید کنند. این مدلها معمولا در برنامههای پردازش زبان طبیعی (NLP) به کار میروند. در این برنامهها، کاربر یک سوال یا درخواست را به زبان عادی وارد میکند و برنامه پاسخ یا نتیجه مربوطه را تولید میکند.
مدلهای زبانی بزرگ (LLM) نسخه پیشرفته و گستردهتر مدلهای زبانی در هوش مصنوعی هستند. آنها با استفاده از حجم عظیمی از دادهها (معمولا بیش از یک میلیارد پارامتر) آموزش دیدهاند تا بتوانند روابط پیچیده زبانی را درک کرده و براساس آن، محتوای جدید تولید کنند. پارامترها در واقع متغیرهایی هستند که مدل یادگیری ماشین براساس آنها آموزش میبیند. هرچه تعداد پارامترها بیشتر باشد، قابلیتهای مدل نیز گستردهتر خواهد شد. بنابراین LLMها میتوانند کارهای پیچیدهتری مانند پاسخگویی به سوالات، خلاصه نویسی، ترجمه و حتی تولید متون طولانی را با دقت بالاتری انجام دهند.
مدلهای زبانی بزرگ مدرن که از سال 2017 ظهور کردهاند، از معماری پیشرفتهای به نام ترنسفورمر استفاده میکنند. این معماری، شبکههای عصبی مصنوعی ویژهای هستند که با تعداد بسیار زیادی پارامتر (گاه میلیاردها پارامتر) آموزش دیده است. این ویژگیها به LLMها این قابلیت را میدهد تا متون را با دقت بسیار بالایی درک کرده و پاسخهای مناسب را با سرعت بالا تولید کنند. همین امر سبب شده تا فناوری هوش مصنوعی بتواند در زمینههای بسیار متنوعی به کار گرفته شود.
LLMهای بسیار قدرتمند و تاثیرگذاری وجود دارند که به عنوان “مدلهای پایه” شناخته میشوند. این اصطلاح در سال 2021 توسط موسسه استنفورد برای هوش مصنوعی انسان محور ابداع شد. منظور از مدل پایه، مدلهایی است که آنقدر بزرگ و گسترده هستند که میتوانند به عنوان یک پایه و زیربنای اصلی برای بهینه سازی و تخصصی سازی بیشتر در کاربردهای خاص مورد استفاده قرار گیرند.
هوش؟ مصنوعی | مرز بین هوشمندی انسان و ماشین چقدر نزدیک است؟
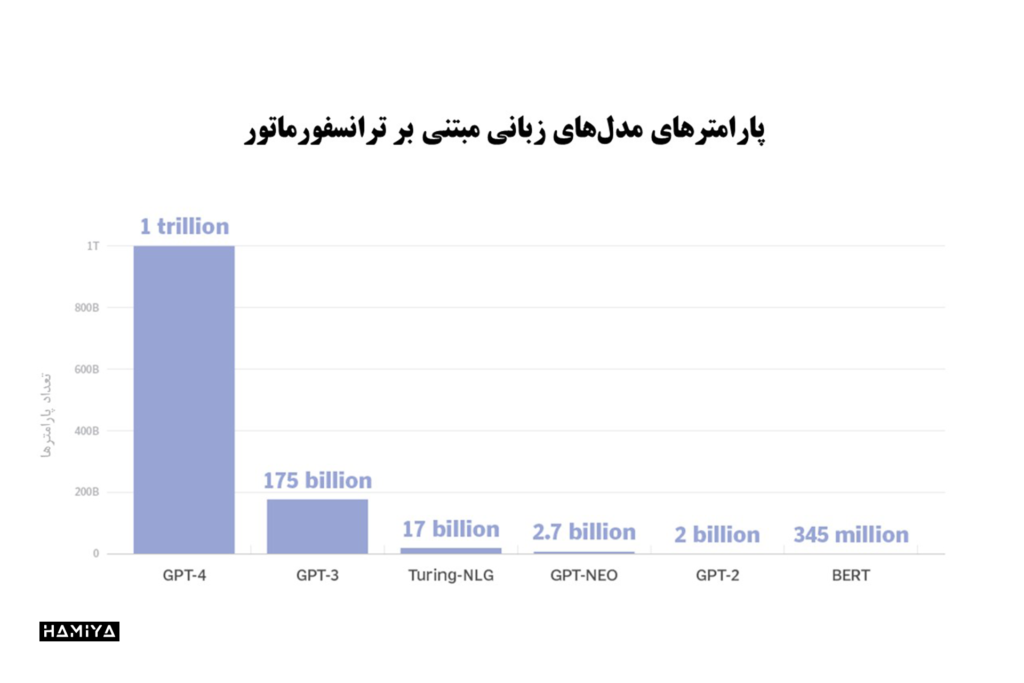
نمونههایی از LLM
- Bert
- مدل هوش مصنوعی Claude
- Cohere
- Falcon 40B
- Galactica
- GPT-3
- GPT-3.5 یا همان ChatGPT
- GPT-4
- مدل هوش مصنوعی GPT-4o
- LLaMa 1
- OpenAI o1
چرا LLMها برای مشاغل مهم میشوند؟
هوش مصنوعی روز به روز جایگاه مهمتری در دنیای کسب و کار پیدا میکند. این امر از طریق استفاده از مدلهای زبانی بزرگ و ابزارهای یادگیری ماشین محقق میشود. اما در طراحی و پیاده سازی این مدلها، باید سادگی و سازگاری را سرلوحه قرار داد. شناسایی مسائل قابل حل، درک صحیح دادههای تاریخی و اطمینان از دقت آنها نیز از ملزومات اساسی این فرآیند به شمار میرود.
مزایای استفاده از یادگیری ماشین در کسب و کارها معمولا به چهار دسته تقسیم میشوند:
- افزایش کارایی و بهرهوری،
- افزایش اثربخشی و نتایج بهتر،
- بهبود تجربه مشتریان و کارکنان،
- تحول و پیشرفت در مدل کسب و کار.
با توجه به این مزایای چشمگیر، شرکتها روز به روز در حال سرمایه گذاری و بکارگیری بیشتر فناوریهای یادگیری ماشین در کسب و کارهای خود هستند.
مدلهای زبانی بزرگ چگونه کار میکنند؟
LLMها رویکرد پیچیدهای دارند که شامل چندین مؤلفه است.
در لایه بنیادی، یک مدل LLM باید روی حجم عظیمی از دادهها که معمولا در مقیاس پتابایت هستند و گاهی “مجموعه نوشتهها” نامیده میشوند، آموزش ببیند. این آموزش معمولاً با روش یادگیری بدون نظارت آغاز میشود که در آن، مدل روی دادههای بدون ساختار (unstructured data) و برچسب نخورده (unlabeled data) آموزش میبیند. مزیت این روش این است که دادههای خام بسیار بیشتری در دسترس است. در این مرحله، مدل شروع به استخراج روابط میان کلمات و مفاهیم مختلف میکند.
گام بعدی برای برخی از LLMها آموزش و تنظیم دقیق با نوعی یادگیری با نظارت است. در این مرحله، برخی از برچسبگذاری دادهها رخ داده است که به مدل کمک میکند تا مفاهیم مختلف را با دقت بیشتری شناسایی کند.
در مرحله بعد، مدل زبانی بزرگ از معماری پیشرفته ترنسفورمر و تکنیک یادگیری عمیق بهره میگیرد. معماری ترنسفورمر به این مدل امکان میدهد تا با استفاده از مکانیسم “خودنگرشی” (self-attention)، روابط پیچیده بین کلمات و مفاهیم مختلف را درک کند. در این مکانیسم، مدل به هر آیتم (توکن) امتیازی میدهد که “وزن” نامیده میشود و نشان میدهد آن آیتم تا چه اندازه در ارتباط با آیتم مورد نظر است. این فرایند به مدل کمک میکند تا معانی و روابط را بهتر درک کند و پاسخهای دقیقتری تولید نماید. البته درک دقیق معانی و روابط بین کلمات مستلزم فهم عمیق از مفاهیمی مانند “توکن”، “محدودیت توکن”، “بیشترین خروجی” و “پنجره کانالی” میباشد که با مطالعهی مقالهی “رمزگشایی از دنیای هوش مصنوعی و LLM: از توکنها تا پنجرههای کانالی” میتوانید به درک بهتری از این موضوعات دست یابید.
هنگامی که یک مدل زبانی بزرگ (LLM) به درستی آموزش داده شد، پایه و زیرساختی فراهم میشود که بر مبنای آن میتوان از هوش مصنوعی برای اهداف کاربردی مختلف بهره برد. با ارائه یک پرسش یا سوال اولیه (پرامپت) و پرامپت مهندسی شده به یک مدل، این مدل میتواند با استفاده از توان استنتاج و استنباط خود، پاسخ یا خروجی مناسبی را تولید کند. این خروجی میتواند پاسخ به یک سوال، یک متن جدید، خلاصهای از یک متن طولانی، تحلیل و گزارشی از نگرشها و ایدههای خاص و حتی ایجاد عکس با هوش مصنوعی باشد.
مدلهای زبان بزرگ برای چه مواردی استفاده میشوند؟
مدلهای زبانی بزرگ یا LLMها ابزارهای قدرتمندی هستند که کاربردهای گستردهای در زمینه پردازش زبان طبیعی (NLP) دارند. این مدلها میتوانند در موارد متنوعی به کار گرفته شوند از جمله:
- تولید متن: توانایی تولید متن در مورد هر موضوعی که LLM در مورد آن آموزش دیده است، یک مورد استفاده اولیه است.
- ترجمه: برای LLMهایی که در چندین زبان آموزش دیدهاند، توانایی ترجمه از یک زبان به زبان دیگر یک ویژگی مشترک است.
- خلاصه نویسی: خلاصه کردن پاراگرافها یا چندین صفحه متن، نمونههایی از عملکرد مفید LLM است.
- بازنویسی محتوا: بازنویسیِ بخشی از متن، یکی دیگر از قابلیتهای آن است.
- طبقه بندی و دسته بندی: یک LLM قادر به طبقه بندی و دسته بندی محتوا است.
- تجزیه و تحلیل حساسیت: اکثر LLMها میتوانند برای تجزیه و تحلیل حساسیت استفاده شوند تا به کاربران کمک کنند تا هدف یک محتوا یا یک پاسخ خاص را بهتر درک کنند.
- هوش مصنوعی مکالمهای و رباتهای چت: LLMها میتوانند مکالمه با کاربر را به گونهای فعال کنند که معمولاً طبیعیتر از نسلهای قدیمی فناوریهای هوش مصنوعی است. مانند GPT-4o.
یکی از رایجترین کاربردهای LLMها، استفاده در رباتهای گفتگویی یا چت باتهاست که میتوانند به شکل طبیعی و روان با کاربران تعامل کنند. نمونه بارز آن، چت بات ChatGPT است که توسط OpenAI بر پایه مدل GPT-3.5 توسعه یافته است. این چت بات میتواند به سوالات به زبان طبیعی پاسخ دهد، متون را تولید یا خلاصه کند و حتی حساسیت را تجزیه و تحلیل نماید.
مزایای مدلهای زبانی بزرگ چیست؟
مدلهای زبانی بزرگ یا LLMها دارای مزایای چشمگیری هستند که آنها را برای سازمانها و کاربران بسیار جذاب میکند:
- قابلیت توسعه و سازگاری: LLMها میتوانند به عنوان پایه و زیرساختی برای کاربردهای سفارشی سازی شده عمل کنند. با آموزش اضافی روی یک LLM، میتوان مدلهای تخصصی متناسب با نیازهای خاص یک سازمان یا مصرف کننده ایجاد کرد.
- انعطاف پذیری باﻻ: یک LLM قابلیت استفاده در پلتفرمها و حوزههای بسیار متنوعی را برای سازمانها، کاربران و برنامههای مختلف دارد.
- کارایی و سرعت عمل بالا: مدلهای زبانی بزرگ مدرن معمولا بسیار سریع عمل میکنند و میتوانند پاسخهای فوری و بدون تاخیر تولید کنند.
- دقت بالا: با افزایش تعداد پارامترها و حجم دادههای آموزشی، معماریِ ترنسفرمر این مدلها قادر است سطوح بسیار بالایی از دقت را ارائه دهد.
- آموزش ساده: بسیاری از LLMها با دادههای بدون برچسب آموزش میبینند که این روند را تسریع میبخشد.
- افزایش بهره وری: با خودکارسازی کارهای تکراری، LLMها میتوانند در زمان و منابع کارکنان صرفه جویی کنند.
چالشها و محدودیتهای مدلهای زبان بزرگ چیست؟
در حالی که استفاده از LLM مزایای زیادی دارد، چالشها و محدودیتهای متعددی را نیز به همراه دارند که از جملهی آنها میتوان به موارد زیر اشاره کرد:
- هزینههای توسعه: برای اجرا، LLMها معمولاً به مقادیر زیادی سخت افزار واحد پردازش گرافیکی (GPU) گران قیمت و مجموعه دادههای عظیم نیاز دارند.
- هزینههای عملیاتی: پس از دوره آموزش و توسعه، هزینه راه اندازی LLM برای سازمان میزبان میتواند بسیار بالا باشد.
- سوگیری (Bias): مدلهای زبانی بزرگ ممکن است دارای تعصبات و جانبداریهای ناخواسته نسبت به گروههای خاص مانند اقلیتهای نژادی، جنسیتی یا قومی باشند که ناشی از دادههای آموزشی دارای تعصبات و جانبداریهای انسانی است.
- دغدغههای اخلاقی: LLMها میتوانند مشکلاتی در مورد حریم خصوصی دادهها داشته باشند و محتوای مضر ایجاد کنند.
- توضیحپذیری: توانایی توضیح اینکه چگونه یک LLM توانست یک نتیجه خاص ایجاد کند برای کاربران آسان یا واضح نیست.
- توهم: توهم هوش مصنوعی زمانی اتفاق میافتد که یک LLM پاسخی نادرست ارائه میدهد که مبتنی بر دادههای آموزشدیده نیست.
- پیچیدگی: با میلیاردها پارامتر، LLMهای مدرن فناوریهای فوق العاده پیچیدهای هستند که به هنگام مواجه شده با مشکل، عیب یابی این فناوریها میتواند بسیار پیچیده باشد.
- توکنهای اشتباه (Glitch tokens)1: در برخی موارد، مدلهای زبانی بزرگ ممکن است در میان متن منسجم و معنادار خود، توکنهای بدون ارتباط و بی معنی را تولید کنند که به آنها Glitch tokens گفته میشود. این توکنها میتوانند مانند اشتباهات تایپی یا جملات نیمه تمام به نظر برسند. وجود Glitch tokens میتواند باعث اختلال در روانی و انسجام متن شود و تجربه کاربری را مختل کند. علت اصلی آن ممکن است نقص در مدل یا دادههای آموزشی باشد.
- خطرات امنیتی: از LLMها میتوان برای بهبود حملات فیشینگ (phishing attacks) به کارکنان استفاده کرد.
انواع مختلف مدلهای زبان بزرگ چیست؟
مجموعهای از اصطلاحات در حال تکامل برای توصیف انواع مختلف مدلهای زبان بزرگ وجود دارد. از انواع رایج میتوان به موارد زیر اشاره کرد:
- مدل Zero-shot: این یک مدل بزرگ و تعمیمیافته است که بر روی مجموعهای از دادههای عمومی آموزش داده شده است و میتواند نتایج نسبتاً دقیقی را برای موارد استفاده عمومی، بدون نیاز به آموزش اضافی ارائه دهد. GPT-3 اغلب یک مدل Zero-shot در نظر گرفته میشود.
- مدلهای با تنظیم دقیق یا با دامنه خاص (Fine-tuned or domain-specific models): آموزشهای اضافی بر روی یک مدل صفر شات (Zero-shot model) مانند GPT-3 میتواند به یک مدل دقیق و مختص دامنه منجر شود. یک مثال برای این موضوع، OpenAI Codex است؛ یک مدل زبانی بزرگ با دامنه خاص برای برنامه نویسی که مبتنی بر GPT-3 است.
- مدل بازنمایی زبان (Language representation model): یکی از نمونههای مدل بازنمایی زبان Google’s Bert است که از یادگیری عمیق و ترانسفورماتورهای مناسب برای NLP استفاده میکند.
- مدل چندوجهی (Multimodal model): در ابتدا LLMها به طور خاص فقط برای متن تنظیم میشدند، اما با رویکرد چندوجهی، میتوان هم متن و هم تصاویر را مدیریت کرد. GPT-4 نمونهای از این نوع مدل است.
آینده مدلهای زبانی بزرگ
آینده مدلهای زبانی بزرگ هنوز در دستان انسانهایی است که به توسعه این فناوری میپردازند. اگرچه ممکن است روزی برسد که خود این مدلها بتوانند منابع جدید خلق کنند، اما در آیندهی نزدیک، نسل جدید LLMها به معنای واقعی کلمه دارای هوش مصنوعی عمومی (AGI: artificial general intelligence) یا هوشیاری نخواهند بود. با این حال، روند بهبود و ارتقای توانمندیهای این مدلها به صورت مستمر ادامه خواهد داشت و شاهد نمونههای “هوشمندتر” آنها خواهیم بود.
مدلهای زبانی بزرگ در آینده کاربردهای تجاری گستردهتری خواهند یافت. توانایی آنها در ترجمه محتوا در حوزههای مختلف بیشتر و بیشتر خواهد شد. این امر سبب میشود تا این مدلها برای کاربران تجاری با سطوح مختلفی از تخصص فنی، کاربردیتر و قابل استفادهتر شوند.
مدلهای زبانی بزرگ در آینده بر روی حجم بسیار بزرگتری از دادهها آموزش خواهند دید. این دادهها برای افزایش دقت و کاهش سوگیریهای احتمالی، فیلتر شدهتر خواهند شد. یکی از راههای این امر، افزودن قابلیتهای بررسی صحت و واقعیت اطلاعات است. همچنین انتظار میرود نسل آینده LLMها نسبت به نمونههای فعلی، در ارائه مستندات و توضیحات بهتر در مورد چگونگی دستیابی به یک نتیجه خاص، عملکرد مطلوبتری داشته باشند.
در آینده، یکی از راهکارهای بهبود دقت مدلهای زبانی بزرگ، توسعه نمونههای تخصصی و ویژه برای صنایع یا کاربردهای خاص خواهد بود. همچنین به کارگیری تکنیکهایی مانند یادگیری تقویتی از بازخورد انسانی، که OpenAI برای آموزش ChatGPT از آن استفاده میکند، میتواند به افزایش دقت این مدلها کمک شایانی کند. از سوی دیگر، نوع جدیدی از LLMها با عنوان “نسل افزوده شده بازیابی” مانند Realm شرکت گوگل وجود دارند که امکان آموزش و استنتاج بر روی مجموعه بسیار خاص دادهها را فراهم میکنند، درست مشابه آنچه که امروزه کاربران در جستجوی اینترنتی انجام میدهند.
در آینده نیز تلاشهای مستمری برای بهینه سازی ابعاد و زمان آموزش مدلهای زبانی بزرگ صورت خواهد گرفت. یکی از این تلاشها، توسعه مدل “لاما” (Llama) توسط شرکت متا است. نسخه دوم این مدل که در جولای 2023 منتشر شد، کمتر از نیمی از پارامترهای مدل GPT-3 و تعداد ناچیزی از پارامترهای GPT-4 را داراست. با این حال، حامیان لاما ادعا میکنند که این مدل کوچکتر میتواند از دقت بالاتری نیز برخوردار باشد.
از سوی دیگر، استفاده گسترده از مدلهای زبانی بزرگ در سازمانها میتواند موجب ایجاد مشکلات جدیدی شود که باید به آنها توجه کرد. یکی از این مشکلات، استفاده غیرمجاز و غیررسمی از این مدلها در قالب “فناوری اطلاعات سایه” (shadow IT)2 است که میتواند مسائل حریم خصوصی دادهها را در پی داشته باشد. بنابراین مدیران ارشد اطلاعات باید سیاستها و آموزشهایی را برای نحوه استفاده درست از LLMها در سازمان تدوین کنند. همچنین امنیت سایبری یکی دیگر از حوزههایی است که میتواند از این مدلها تهدید شود. مهاجمان میتوانند از LLMها برای نوشتن ایمیلهای فیشینگِ بسیار گمراه کننده و یا دیگر ارتباطات مخرب استفاده کنند.
اگرچه استفاده از مدلهای زبانی بزرگ در سازمانها با چالشهایی از قبیل مسائل امنیتی و حریم خصوصی همراه است، اما آینده این فناوری همچنان روشن و امیدوار کننده به نظر میرسد؛ زیرا LLMها در حال تکامل مداوم هستند و روشهای جدیدی برای ارتقای آنها ارائه میشود تا بتوانند به افزایش بهره وری انسانها کمک کنند.
- توکنهای اشتباه (Glitch tokens) کلماتی هستند که باعث خروجی غیرعادی در مدلهای زبان بزرگ (LLM) میشوند. هنگامی که یک LLM یک “توکن گلیچ” را پردازش میکند، ممکن است خروجی بیمعنی، متناقض یا غیرمرتبط تولید کند.
↩︎ - Shadow IT یا “فناوری اطلاعات سایهای” به سخت افزار یا نرم افزارهایی گفته میشود که کارمندان یک سازمان بدون اطلاع یا تایید بخش مرکزی فناوری اطلاعات (IT)، از آنها استفاده میکنند.
↩︎
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





