هوش مصنوعی در دنیای امروز اهمیت بسیار زیادی دارد و نقشی کلیدی در زندگی روزمره ما ایفا میکند. با پیشرفتهای چشمگیر در این حوزه، آشنایی با مفاهیم اصلی و درک هوش مصنوعی ضروری است. در این راستا، مقاله حاضر به بررسی یکی از مهمترین شاخههای یادگیری ماشین، یعنی ” یادگیری نظارت نشده” میپردازد. امروزه، هوش مصنوعی به عنوان یک نیروی محرک در بسیاری از صنایع ظهور کردهاست. از تشخیص الگو در پزشکی گرفته تا توصیههای شخصیسازی شده در خردهفروشی، انواع مدلهای یادگیری ماشین راه را برای نوآوریهای بیشماری هموار کردهاست. با این حال، برای درک عمیقتر این فناوری، آشنایی با انواع مختلف آن ضروری است. در همین راستا، این مقاله به بررسی “یادگیری نظارت نشده” میپردازد؛ روشی که در آن ماشینِ بدون دادههای برچسبدار، الگوها و ساختارهای پنهان در دادهها را کشف میکند. بااستفاده از مثالهای کاربردی و توضیحات ساده، شما همراهان هامیا میتوانید درک عمیقی از این شاخه مهم یادگیری ماشین کسب کنید. همراه هامیا ژورنال باشید و از این فرصت یادگیری لذت ببرید.
فهرست مطالب
یادگیری بدون نظارت چیست؟
یادگیری بدوننظارت (یا یادگیری ماشین بدون نظارت) یکی از تکنیکهای یادگیری ماشین (ML) است که از الگوریتم های هوش مصنوعی (AI) برای شناسایی الگوها در مجموعه دادههایی که طبقهبندی یا برچسبگذاری نشدهاند، استفاده میکند.
مدلهای یادگیری نظارت نشده در هنگام آموزش مجموعه دادهها به نظارت نیاز ندارند و این امر آنها را به تکنیکی ایدهآل در یادگیری ماشین برای کشف الگوها، گروه بندیها و تفاوتها در دادههای بدون ساختار تبدیل میکند. این مدلها برای فرآیندهایی مانند بخشبندی مشتریان، تحلیل اکتشافی دادهها یا تشخیص تصویر بسیار مناسب هستند.
نقشه راه جامع علم داده : چگونه یک دانشمند داده موفق شویم؟
الگوریتم های یادگیری بدون نظارت میتوانند نقاط داده موجود در مجموعه دادهها را بدون نیاز به هیچ راهنمایی خارجی برای انجام آن کار، طبقهبندی، برچسبگذاری و گروه بندی کنند. به عبارت دیگر، یادگیری بدون ناظر به یک سیستم اجازه میدهد تا به طور مستقل الگوهای موجود در مجموعه دادهها را شناسایی کند.
در یادگیری بدوننظارت، یک سیستم هوش مصنوعی اطلاعات طبقهبندینشده را بر اساس شباهتها و تفاوتها گروهبندی میکند، حتی اگر هیچ دستهبندی از پیش تعیینشدهای وجود نداشته باشد.
سیستمهای هوش مصنوعی که قادر به یادگیری بدون نظارت هستند، اغلب با مدلهای یادگیری تولیدکننده مرتبط هستند، اگرچه ممکن است از رویکرد مبتنی بر بازیابی نیز استفاده کنند که بیشتر با یادگیری تحت نظارت مرتبط است. چتباتها، خودروهای خودران، برنامههای تشخیص چهره، سیستمهای خبره و رباتها از جمله سیستمهایی هستند که از رویکردهای یادگیری با نظارت یا بدون نظارت استفاده میکنند. یادگیری بدون نظارت همچنین به عنوان یادگیری ماشین بدون نظارت شناخته میشود.
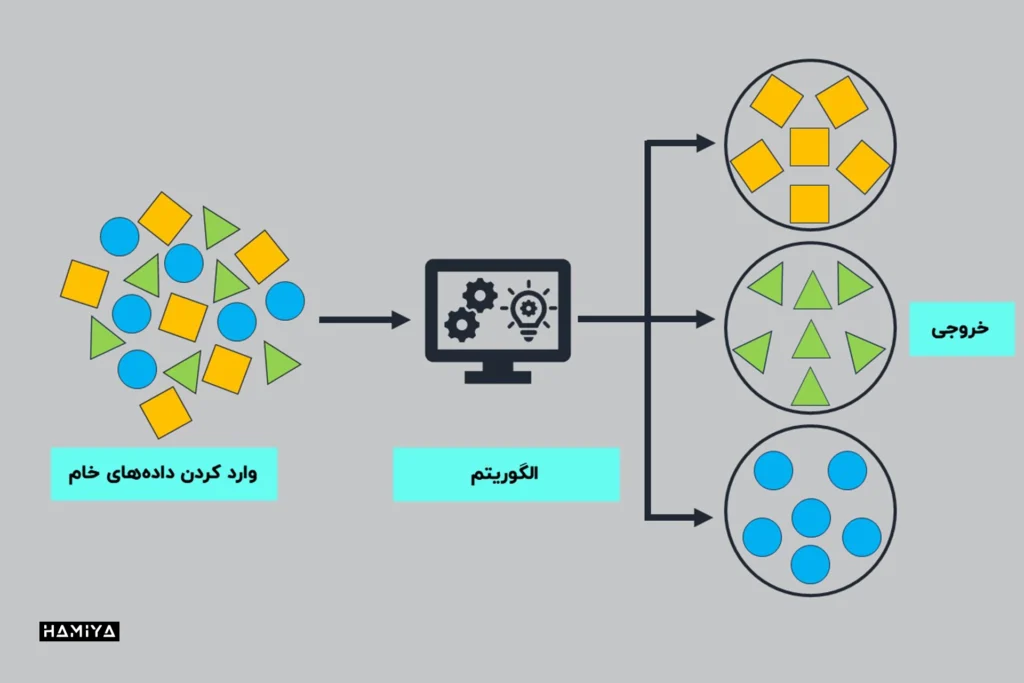
یادگیری بدون نظارت چگونه کار میکند؟
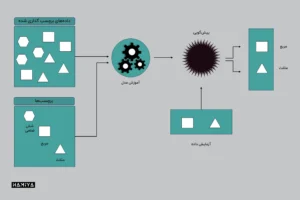
یادگیری بدوننظارت زمانی آغاز میشود که مهندسان یادگیری ماشین یا دانشمندان داده، مجموعه دادهها را از طریق الگوریتم ها برای آموزش آنها عبور میدهند. در مجموعه دادههایی که برای آموزش چنین سیستمهایی استفاده میشوند، هیچ برچسب یا دستهبندی وجود ندارد؛ هر قطعه از دادهای که در طول آموزش از طریق الگوریتم ها عبور میکند، یک نمونه یا شیء ورودی بدون برچسب است.
هدف یادگیری بدون ناظر این است که الگوریتم ها بتوانند الگوها را در مجموعه دادههای آموزشی شناسایی کنند و اشیاء ورودی را بر اساس الگوهایی که خود سیستم شناسایی میکند، دستهبندی نمایند. الگوریتم ها با استخراج اطلاعات یا ویژگیهای مفید از مجموعه دادهها، ساختار زیربنایی آنها را تحلیل میکنند. بنابراین، انتظار میرود این الگوریتم ها با جستجوی روابط بین هر نمونه یا شیء ورودی، خروجیهای خاصی را توسعه دهند.
برای مثال، الگوریتم های یادگیری بدون نظارت ممکن است مجموعه دادههایی حاوی تصاویر حیوانات را دریافت کنند. این الگوریتم ها میتوانند حیوانات را در دستهبندیهایی مانند پستانداران (دارای خز)، خزندگان (دارای فلس) و پرندگان (دارای پر) طبقهبندی کنند. سپس الگوریتم ها با یادگیری تشخیص تمایزات درون هر دسته، تصاویر را در زیرگروههای خاصتری گروهبندی میکنند.
الگوریتم ها این کار را با کشف و شناسایی الگوها انجام میدهند. در یادگیری نظارت نشده، تشخیص الگو بدون اینکه دادههایی به سیستم داده شود تا بتواند دستههای خاصی را تشخیص دهد، اتفاق میافتد.
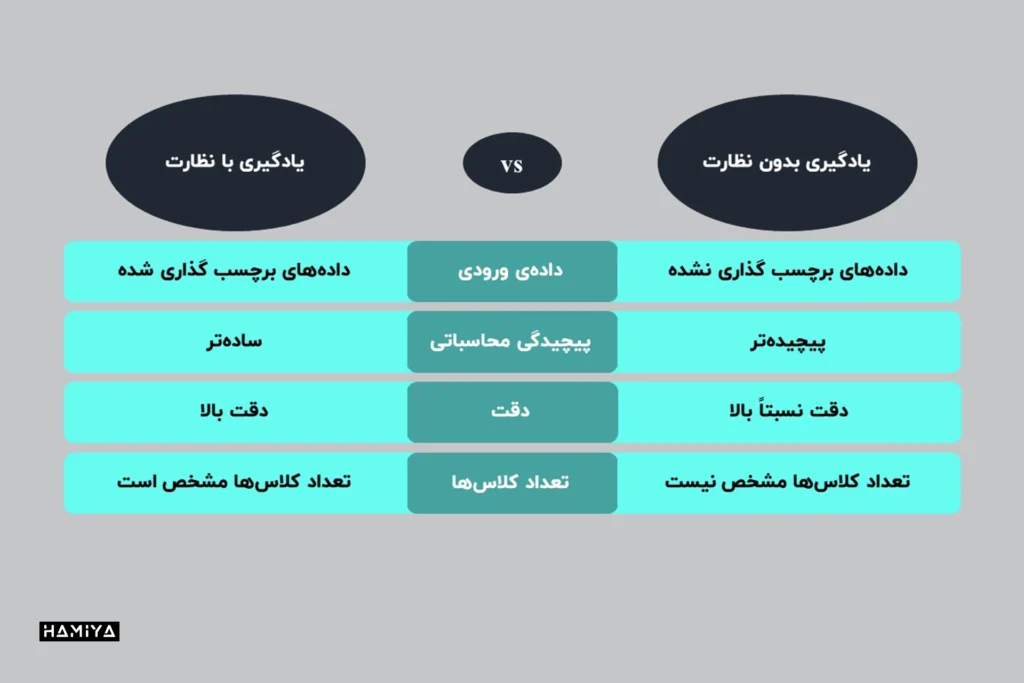
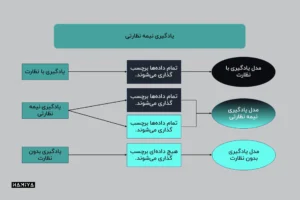
یادگیری بدون نظارت ، یادگیری با نظارت و یادگیری نیمه نظارتی
یادگیری با نظارت، درست مانند یادگیری بدون نظارت ، یکی از تکنیکهای یادگیری ماشین است، اما در یادگیری با نظارت، دانشمندان داده، الگوریتم ها را با دادههای آموزشی برچسبگذاریشده تغذیه میکنند و متغیرهایی را که میخواهند الگوریتم ارزیابی کند، تعریف میکنند.
برخلاف یادگیری بدوننظارت ، در یادگیری با نظارت، هم دادههای ورودی و هم خروجیهای الگوریتم در دادههای آموزشی مشخص شدهاند. بااستفاده از مثال حیوانات، دانشمندان داده، عکسهایی از هر حیوان را به الگوریتم تغذیه میکنند و برای هر عکسی که در دادههای آموزشی استفاده میشود برچسبی ایجاد میکنند تا نشان دهد که آیا یک تصویر حاوی حیوان است و به چه دستهای تعلق دارد.
مدلهای یادگیری با نظارت تا زمانی آموزش داده میشوند که بتوانند الگوها و روابط بین دادههای ورودی و برچسبهای خروجی را تشخیص دهند. طبقهبندی، درختان تصمیمگیری، رگرسیون و مدلسازی پیشبینی، انواع رایج الگوریتم های یادگیری با نظارت هستند.
در مقایسه یادگیری با نظارت و یادگیری بدون ناظر ، یادگیری با نظارت از مجموعه دادههای برچسبگذاریشده برای آموزش الگوریتم ها برای شناسایی و طبقهبندی براساس برچسبهای ارائهشده استفاده میکند. یادگیری بدون نظارت نسبت به مدل یادگیری با نظارت غیر قابل پیشبینیتر است. در حالی که یک سیستم هوش مصنوعی یادگیری نظارت نشده ممکن است به تنهایی نحوه جداسازی گربه از سگ را بفهمد، همچنین ممکن است برای مقابله با نژادهای غیرمعمول، دستههای پیشبینینشده و ناخواستهای را اضافه کند که به جای نظم، باعث ایجاد سردرگمی شود.
مهندسان یادگیری ماشین یا دانشمندان داده میتوانند برای آموزش الگوریتم های خود از ترکیبی از دادههای برچسبگذاریشده و بدون برچسب استفاده کنند. این گزینه ترکیبی به طور مناسب “یادگیری نیمه نظارتی” نامیده میشود.
در یادگیری نیمه نظارتی، الگوریتم با ترکیبی از دادههای برچسبگذاریشده و بدون برچسب آموزش داده میشود. این فرایند با مجموعهای از پیشنهادات و دستهبندیهای انسانی آغاز میشود و سپس از یادگیری بدوننظارت برای کمک به فرآیند یادگیری با نظارت استفاده میکند. یادگیری نیمه نظارتی این آزادی را میدهد که در عین حال تحت هدایت دیدگاه انسانی، برای دادهها برچسب تعریف کنید.
یک تکنیک دیگر یادگیری ماشین، یادگیری تقویتی (reinforcement learning) است که بر اساس پاداش دادن به رفتارهای مطلوب و تنبیه رفتارهای نامطلوب بنا شدهاست. در این فرآیند، توسعهدهندگان روشی برای اختصاص دادن مقادیر مثبت به اعمال مطلوب و مقادیر منفی به رفتارهای نامطلوب ایجاد میکنند.
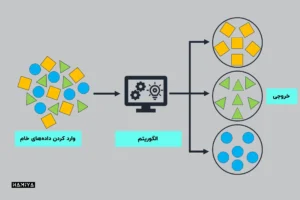
خوشهبندی و انواع دیگر یادگیری بدون نظارت
یادگیری نظارت نشده اغلب بر روی خوشهبندی (clustering) تمرکز دارد. خوشهبندی یعنی گروه بندی اشیاء یا نقاط دادهای مشابه در یک خوشه و قرار دادن اشیاء غیرمشابه در خوشههای دیگر.
مهندسان یادگیری ماشین و دانشمندان داده میتوانند از الگوریتم های مختلفی برای خوشهبندی استفاده کنند، به طوری که خود الگوریتم ها بر اساس نحوه عملکردشان در دستههای مختلفی قرار میگیرند. الگوریتم های خوشهبندی را میتوان در دستههای زیر قرار داد:
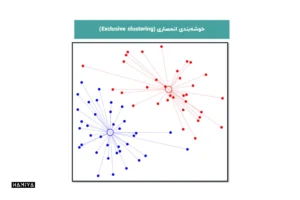
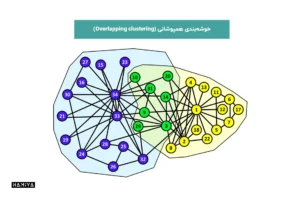
- خوشهبندی انحصاری (Exclusive clustering): این شکل از گروه بندی دادهها مشخص میکند که یک نقطه داده فقط میتواند در یک خوشه وجود داشته باشد.
- خوشهبندی همپوشانی (Overlapping clustering): این شکل از گروه بندی دادهها به نقاط داده اجازه میدهد تا با سطوح عضویت متفاوت به چندین خوشه تعلق داشته باشند.
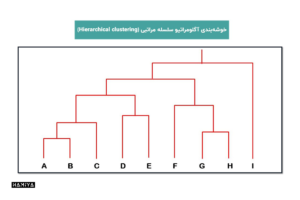
- خوشهبندی سلسله مراتبی (Hierarchical clustering): این شکل از گروه بندی دادهها به دو دسته تقسیم میشود: خوشهبندی آگلومراتیو یا روش پایین به بالا (agglomerative) و خوشهبندی تقسیمی یا بالا به پایین (divisive). در خوشهبندی آگلومراتیو، نقاط داده در ابتدا به عنوان گروههای جداگانه تنظیم میشوند و بعداً ادغام می شوند، در حالی که خوشهبندی تقسیمی یک خوشه داده واحد را میگیرد و بر اساس نقاط داده آن را تقسیم میکند.
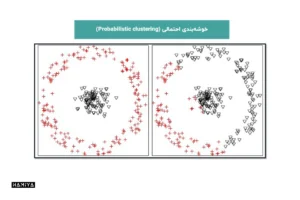
- خوشهبندی احتمالی (Probabilistic clustering): این شکل از گروه بندی نقاط داده بر اساس احتمال تعلق داشتن آنها به توزیع خاصی از دادهها انجام میشود. مدل مخلوط گاوسی (Gaussian Mixture Model) به طور معمول برای نشان دادن زیرمجموعههایی درون کل جمعیت به کار میرود.
برخی از الگوریتم های پرکاربردتر در خوشهبندی عبارتند از: الگوریتم خوشهبندی K-means، الگوریتم خوشهبندی K-means فازی، خوشهبندی سلسله مراتبی و الگوریتم های خوشهبندی مبتنی بر تراکم (density-based clustering algorithms).
مزایای یادگیری بدون نظارت
مزایای یادگیری بدون ناظر شامل موارد زیر است:
- یادگیری بدون نظارت برای مدیریت وظایف پیچیده مناسبتر است. در جایی که دادههای ورودی اولیه، پیچیدهتر و بدون ساختار هستند، یادگیری بدون نظارت نسبت به یادگیری با نظارت مفیدتر است.
- نیاز به تفسیر برچسبها نیست. مهندسان یادگیری ماشین و دانشمندان داده مسئولیت عبور دادن مجموعه دادهها از طریق الگوریتم ها برای آموزش آنها را بر عهده دارند، اما نیازی به تفسیر برچسب برای تک تک نقاط داده ندارند.
- معانی را از دادههای خام استخراج میکنند. ابزارهای هوش مصنوعی در مقایسه با انسان، توانایی ارزیابی سریعتر دادههای خام را دارند.
- یادگیری بدون ناظر برای شناسایی الگوهای زمینهای در مجموعه دادههای بدون ساختار مفید است. یادگیری بدون نظارت را میتوان برای شناسایی عوامل مشترک بین حجم زیادی از نقاط دادهای مختلف به کار برد.
- یادگیری بدون نظارت در لحظه کار می کند. یادگیری نظارت نشده می تواند با داده های لحظهای و آنی برای شناسایی الگوها کار کند.
- یادگیری نظارت شده هزینه کمتری نسبت به یادگیری با نظارت دارد. یادگیری بدوننظارت نیازی به کارِ دستی مرتبط با برچسبگذاری دادهها ندارد، در حالی که یادگیری با نظارت به آن نیاز دارد.
چالشهای یادگیری بدون نظارت
با وجود ویژگیهای مفید یادگیری نظارت نشده ، سازمانها باید معایب آن را نیز در نظر بگیرند، از جمله موارد زیر:
- نتایج میتوانند غیرقابل پیشبینی باشند. ارزیابی دقت خروجیهای یادگیری بدون نظارت دشوار است، زیرا مجموعه دادههای برچسبگذاریشدهای برای تأیید نتایج وجود ندارد.
- زمان بیشتری برای آموزش مدل نیاز است. مدلهای یادگیری بدون نظارت برای تولید خروجی به مجموعه آموزشی بزرگی نیاز دارند و یادگیری از دادههای خام میتواند زمانبر باشد.
- کمبود بینش: شناسایی الگوهای پنهان در مجموعه دادههای طبقهبندی نشده بزرگ، میتواند فرآیند آموزش را دشوارتر کند.
در کنار معایب کلی یادگیری بدوننظارت ، خوشهبندی نیز یک نقطهضعف دیگر دارد. تحلیل خوشهای (cluster analysis) ممکن است شباهتهای میان اشیاء ورودی را بیش از حد برآورد کند. این امر میتواند منجر به نادیده گرفتن نقاط دادهی منحصربهفرد که در برخی سناریوها مثل بخشبندی مشتریان اهمیت دارند، شود. چرا که هدف در بخشبندی مشتریان، درک تک تک مشتریان و عادات خرید منحصربهفرد آنهاست.
کاربردهای یادگیری بدون نظارت
تحلیل اکتشافی دادهها (exploratory analysis) و کاهش ابعاد (dimensionality reduction) دو مورد از کاربردهای رایج یادگیری بدون نظارت هستند.
تحلیل اکتشافی، که از الگوریتم ها برای کشف الگوهای ناشناخته قبلی استفاده میکند، دامنهای از کاربردهای سازمانی دارد. برای مثال، کسبوکارها میتوانند از تحلیل اکتشافی به عنوان نقطهی شروعی برای تلاشهای بخشبندی مشتریان خود استفاده کنند.
در کاهش حجم ابعاد (dimensionality reduction)، الگوریتم ها تعداد متغیرها یا ویژگیها (ابعاد) درون مجموعه دادهها را کاهش میدهند تا بتوان روی ویژگیهای مرتبط برای اهداف مختلف تمرکز کرد. برخی از متخصصان این کار را با گفتن اینکه کاهش حجم داده، نویز موجود در دادهها را حذف میکند، توضیح میدهند. مهندسان یادگیری ماشین اغلب برای انجام این کار از الگوریتم های متغیرهای پنهان مبتنی بر مدل (latent variable model) استفاده میکنند. به عنوان مثال، یک سازمان میتواند از کاهش حجم داده برای خواندن تصاویر تار با کاهش جزئیات پسزمینه استفاده کند.
علاوه بر این، سازمانها می توانند از یادگیری بدون نظارت برای برنامههای زیر استفاده کنند:
- تشخیص ناهنجاری خوشهبندی (Clustering anomaly detection): این تکنیک از یادگیری بدوننظارت برای شناسایی عملکرد دادههای پرت (outlier) در یک گروه بندی مجموعه داده، بدون برچسب گذاری دادهها استفاده میکند.
- استخراج قوانین وابستگی (Association rule mining): یادگیری بدون نظارت ، الگوهای پیشآمدها (occurrence pattern) را در مجموعه دادههای بزرگ و چگونگی تأثیرگذاری آنها بر یکدیگر شناسایی میکند. این کاربرد اغلب برای تشخیص فعالیتهای مشکوک، علائم بیماری و عادات خرید مشتری استفاده میشود.
- امنیت سایبری (Cybersecurity): نرم افزارهای امنیت سایبری که با یادگیری بدون نظارت آموزش دیدهاند، میتواند به شناسایی زمان، مکان و نحوه وقوع احتمالی یک حمله سایبری کمک کند.
- بخشبندی مشتریان (Customer segmentation): گروههای بازاریابی، استراتژیهای تبلیغاتی خود را بر اساس دستهبندیهایی که مشتریانشان در آن قرار میگیرند، شخصیسازی میکنند.
- تصویربرداری پزشکی (Medical imaging): سازمانهای مراقبتهای بهداشتی از ویژگیهای یادگیری ماشین بدون نظارت در دستگاههای رادیولوژی و پاتولوژی برای کمک به تشخیص و درمان بیماران استفاده میکنند.
- اعتبار پیشآگهی (Prognostic validity)1: این کاربرد که اغلب در مراقبتهای درمانی استفاده میشود، بیمارانِ با مشکلات سلامتی مشابه را گروه بندی کرده و پیشبینی میکند که وضعیت این بیماران در طول زمان چگونه خواهد بود.
- سیستمهای توصیهگر (Recommendation engines): سازمانها دادههایی در مورد تاریخچهی جستجوی آنلاین، خرید و بازخورد افراد جمعآوری میکنند تا محتوای شخصیسازیشده را به آنها ارائه دهند.
- اعتبار پیش آگهی به توانایی یک آزمایش یا مدل برای پیشبینی احتمال وقوع یک رویداد در آینده اشاره دارد. این مفهوم در زمینههای مختلفی از جمله پزشکی، روانشناسی و علوم اجتماعی کاربرد دارد. ↩︎
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️