
موضوع مقالهی حاضر به بررسی شبکههای عصبی مصنوعی (ANN) اختصاص دارد، که یکی از مهمترین دستاوردهای فناوری در حوزه هوش مصنوعی و یادگیری ماشین به شمار میرود. این مقاله ابتدا با توضیح چیستی شبکه عصبی و ساختار آن، به بررسی نحوه تقلید این شبکهها از مغز انسان پرداخته و توضیح میدهد که چگونه شبکههای پیچیدهای از گرهها یا نورونهای مصنوعی میتوانند مشکلات پیچیدهای را از طریق یادگیری حل کنند. همچنین، به قابلیت یادگیری و تطبیقپذیری شبکههای عصبی از طریق دادههای آموزشی اشاره شده و روشهای مختلف برای تنظیم وزنهای اتصالات بین واحدهای پردازش توضیح داده میشود.

در ادامه، کاربردهای گسترده شبکههای عصبی مصنوعی در زمینههای مختلف، از جمله تشخیص تصویر، پردازش زبان طبیعی (NLP) و پیشبینیهای پیچیدهای همچون پیشبینی بازار سهام و مدلسازی پیشبینی آب و هوا بررسی میشود. این مقاله همچنین به بررسی انواع مختلف شبکههای عصبی، از جمله شبکههای پیشخور، شبکههای بازگشتی و شبکههای عصبی کانولوشنال (CNN) میپردازد و کاربردهای هر یک را توضیح میدهد. در این بخش، به تفصیل نشان داده میشود که چگونه این شبکهها قادر به شناسایی الگوهای پیچیده در دادهها هستند و چگونه از آنها در صنایع مختلف بهرهبرداری میشود.

مقاله حاظر در بخشهای پایانی به مزایا و معایب شبکههای عصبی مصنوعی میپردازد. از مزایای این شبکهها میتوان به توانایی پردازش موازی و یادگیری روابط غیرخطی اشاره کرد. اما در عین حال، معایبی چون نیاز به سختافزار پیشرفته، عدم شفافیت در نتایج (جعبه سیاه هوش مصنوعی) و وابستگی شدید به دادههای آموزشی نیز مورد بحث قرار گرفتهاند. نهایتاً، مقاله با نگاهی به تاریخچه و سیر تکامل شبکههای عصبی از دهه ۱۹۴۰ تا به امروز، به بررسی نقاط عطفی در توسعه این فناوری پرداخته و چشماندازی از آیندهی آن ارائه میدهد.
فهرست مطالب
شبکه عصبی چیست؟
شبکه عصبی (یا شبکه عصبی مصنوعی) یک مدل یادگیری ماشین (ML) است که برای تقلید عملکرد و ساختار مغز انسان طراحی شده است. شبکههای عصبی شبکههای پیچیدهای از گرههای به هم پیوسته یا نورونها هستند که برای حل مشکلات پیچیده با هم همکاری می کنند.
شبکههای عصبی که به عنوان شبکههای عصبی مصنوعی (Artificial Neural Networks) یا شبکههای عصبی عمیق نیز شناخته میشوند، نوعی فناوری یادگیری عمیق را نشان میدهند که در زیرمجموعهی گستردهتر هوش مصنوعی (AI) طبقهبندی میشود.
شبکههای عصبی مصنوعی در طیف وسیعی از کاربردها از جمله تشخیص تصویر، مدلسازی پیشبینی و پردازش زبان طبیعی (NLP) به طور گسترده مورد استفاده قرار میگیرند. نمونههایی از کاربردهای تجاری قابل توجه از سال ۲۰۰۰ شامل تشخیص دستخط برای پردازش چک، رونوشت گفتار به متن، تجزیه و تحلیل دادههای اکتشاف نفت، پیشبینی آب و هوا و تشخیص چهره است.

شبکه عصبی مصنوعی چگونه کار میکند؟
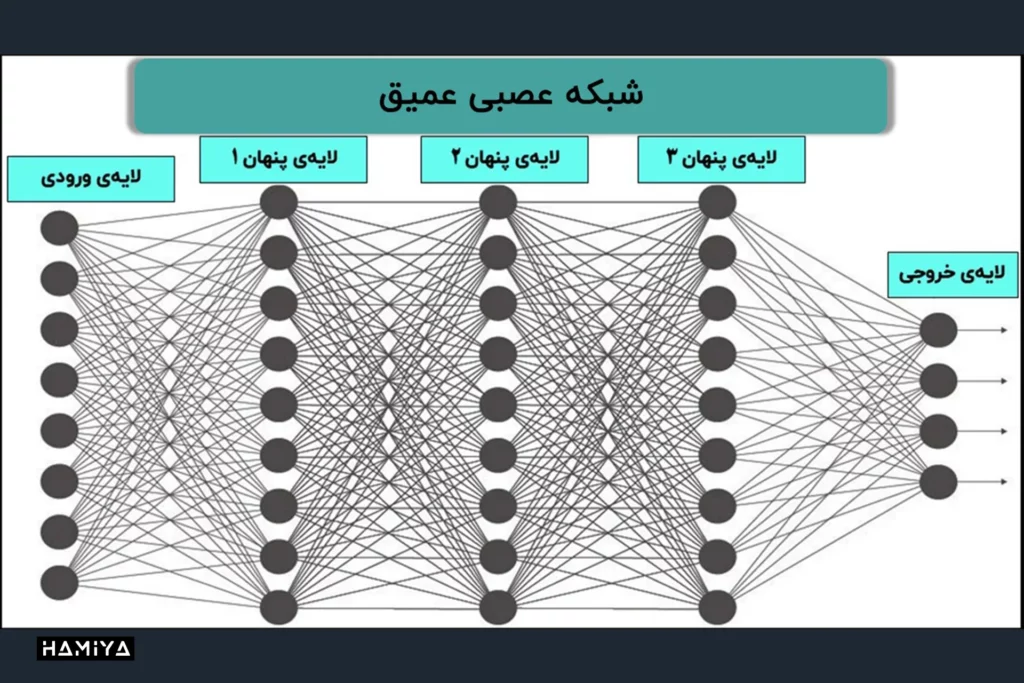
شبکههای عصبی مصنوعی، الگویی الهامگرفته از عملکرد مغز انسان، به عنوان مجموعهای از پردازندههای متصل به هم عمل میکنند. این پردازندهها در لایههای مجزا سازماندهی شده و به صورت موازی فعالیت مینمایند. لایه اولیه، مشابه سلولهای گیرنده نور در چشم انسان، اطلاعات خام ورودی را دریافت میکند. هر لایه بعدی، خروجی لایه پیشین را به عنوان ورودی خود در نظر گرفته و پردازشهای لازم را بر روی آن انجام میدهد. این فرآیند به صورت آبشاری ادامه مییابد تا در نهایت لایه خروجی، پاسخ نهایی سیستم را تولید نماید.
هر واحد پردازشی در شبکه عصبی، حاوی مجموعهای از قوانین و دانش است که از طریق آموزش یا تجربهی قبلی کسب شده است. این واحدها به صورت گسترده به یکدیگر متصل هستند، به طوری که هر واحد (N) با تعداد زیادی از واحدهای لایه قبلی (N-1) و بعدی (N+1) در ارتباط است. این اتصالات، به همراه وزنهای اختصاص داده شده به هر اتصال، تعیین میکنند که چه مقدار از اطلاعات ورودی به واحد بعدی منتقل شود. لایه خروجی، معمولا شامل یک یا چند واحد است که پاسخ قابل تفسیر سیستم را ارائه میدهد.
یکی از ویژگیهای برجستهی شبکههای عصبی مصنوعی، قابلیت یادگیری و تطبیقپذیری آنها است. این شبکهها با استفاده از دادههای آموزشی و تجربههای بعدی، به طور مداوم خود را بهبود میبخشند. مکانیزم اصلی یادگیری در شبکههای عصبی، تنظیم وزنهای اتصالات بین واحدها است. وزنها نشاندهندهی اهمیت نسبی هر ورودی در تولید خروجی صحیح هستند. ورودیهایی که به پیشبینیهای دقیقتر کمک میکنند، وزن بیشتری به خود اختصاص میدهند.
کاربردهای شبکه عصبی مصنوعی
تشخیص تصویر یکی از اولین حوزههایی بود که شبکههای عصبی با موفقیت در آن بکار گرفته شدند. اما کاربردهای این فناوری به بسیاری از زمینههای دیگر گسترش یافتهاست:
- چتباتها
- پردازش زبان طبیعی (NLP)، ترجمه و تولید زبان
- پیشبینی بازار سهام
- برنامهریزی و بهینهسازی در زمینههای مختلف از جمله مهندسی
- کشف و توسعه دارو
- رسانههای اجتماعی
- دستیارهای شخصی
استفادههای اصلی شامل هر فرآیندی است که بر اساس قوانین یا الگوهای دقیق عمل میکند و دارای حجم زیادی از داده است. اگر دادههای درگیر آنقدر زیاد باشد که انسان نتواند در مدت زمان معقولی از آن سر در بیاورد، به احتمال زیاد این فرآیند یک گزینه عالی برای خودکارسازی از طریق شبکههای عصبی مصنوعی است.
شبکه عصبی چگونه یاد میگیرد؟
شبکههای عصبی مصنوعی (ANN) از طریق فرایند آموزش، توانایی یادگیری و تطبیق با دادهها را کسب میکنند (تغذیه میشوند). این فرایند شامل ارائه حجم عظیمی از دادههای آموزشی به شبکه است که هر نمونه شامل یک ورودی و خروجی مطلوب است. به عنوان مثال، برای آموزش یک شبکه جهت تشخیص چهره بازیگران، مجموعهای از تصاویر متنوع از بازیگران، افراد غیر بازیگر، حتی اجسام بیجان، تصاویر ماسکها، مجسمهها و یا حتی چهره حیوانات به عنوان ورودی به شبکه داده میشود. در مقابل هر ورودی، خروجی مورد انتظار (مانند نام بازیگر یا برچسب “غیر بازیگر” یا “غیر انسان”) به شبکه اطلاع داده میشود. این اطلاعات به شبکه اجازه میدهد تا وزنهای داخلی خود را به گونهای تنظیم کند که بتواند ورودیهای مشابه را به خروجیهای صحیح مرتبط سازد.
مکانیزم تنظیم وزنها در شبکههای عصبی بر اساس مقایسه خروجی پیشبینی شده توسط شبکه با خروجی واقعی صورت میگیرد. اگر خروجی پیشبینی شده با خروجی واقعی همخوانی نداشته باشد، وزنهای اتصالاتی که به این خروجی منجر شدهاند، به گونهای تنظیم میشوند که احتمال تکرار این خطا در آینده کاهش یابد. به عنوان مثال، اگر شبکه، به اشتباه تصویری از مهران مدیری را به عنوان دونالد ترامپ تشخیص دهد، وزنهای اتصالاتی که به این تشخیص نادرست منجر شدهاند، کاهش یافته و وزنهای اتصالاتی که به تشخیص صحیح منجر شدهاند، افزایش مییابد.
شبکههای عصبی از مجموعهای از اصول و الگوریتمها برای یادگیری الگوها و تصمیمگیری استفاده میکنند (تصمیمات هر گره در مورد اینکه چه چیزی را بر اساس ورودی های لایه قبلی به لایه بعدی ارسال کند). این اصول شامل آموزش مبتنی بر گرادیان، منطق فازی، الگوریتمهای ژنتیک و روشهای بیزی است. علاوه بر این، میتوان به شبکه قوانین اولیهای در مورد روابط بین ویژگیهای دادهها آموزش داد. برای مثال، میتوان به یک سیستم تشخیص چهره آموزش داد که ابروها بالای چشم قرار دارند یا سبیلها زیر بینی قرار دارند. این قوانین اولیه میتوانند فرایند آموزش را تسریع، دقت شبکه را بهبود و مدل را قدرتمند سازد.
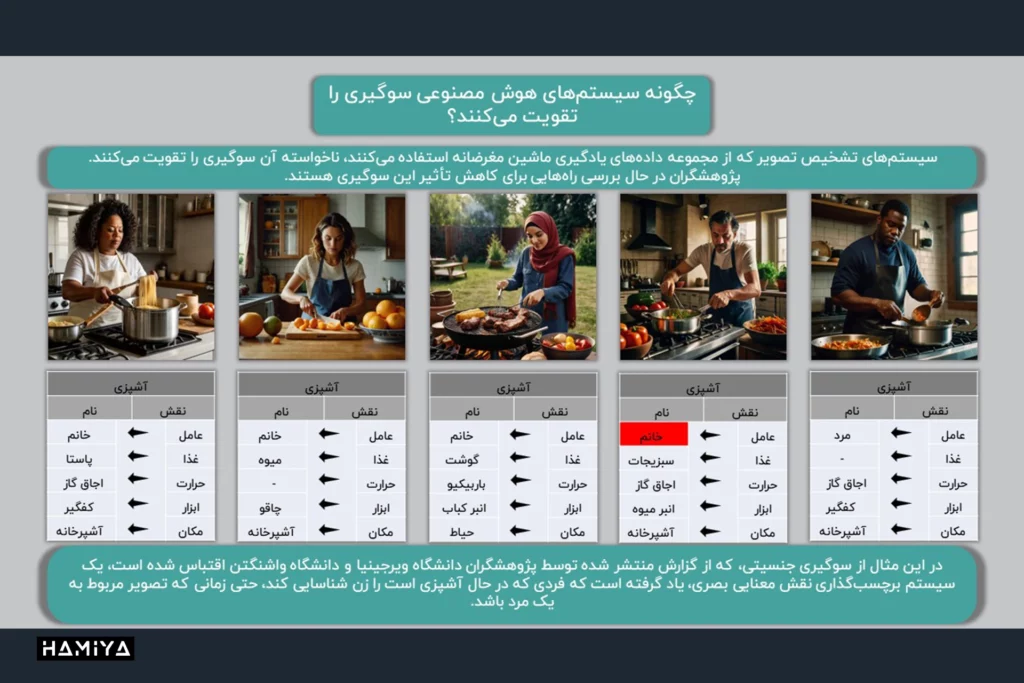
اگرچه ارائه قوانین اولیه به شبکه میتواند مفید باشد، اما انتخاب این قوانین به دقت و دانش قبلی در مورد مسئله مورد مطالعه نیاز دارد. این مرحله از فرایند یادگیری شبکه عصبی، اساس شکل گیری سوگیریها و تعصبات در مدلها میباشد. قوانین نادرست یا بیربط میتوانند عملکرد شبکه را کاهش دهند. علاوه بر این، فرضیات و تعصبات موجود در دادههای آموزشی نیز میتوانند بر عملکرد شبکه تأثیرگذار باشند. به عنوان مثال، اگر دادههای آموزشی حاوی تعصبات نژادی یا جنسیتی باشند، شبکه نیز این تعصبات را یاد گرفته و در پیشبینیهای خود منعکس خواهد کرد. بنابراین، انتخاب دادههای آموزشی بیطرف و متنوع از اهمیت بالایی برخوردار است (لازم به ذکر است که تقریباً هیچ دادهای بیطرف نیست!).
انواع شبکه عصبی
یکی از ویژگیهای بارز شبکههای عصبی مصنوعی، عمق آنهاست که به تعداد لایههای پنهان موجود بین لایه ورودی و خروجی اشاره دارد. به همین دلیل، اصطلاح “شبکه عصبی” اغلب به جای “یادگیری عمیق” به کار میرود. علاوه بر عمق، شبکههای عصبی را میتوان بر اساس تعداد گرههای موجود در هر لایه پنهان و همچنین تعداد لایههای ورودی و خروجی هر گره توصیف نمود. تنوع در طراحی معماری شبکههای عصبی، امکان انتشار اطلاعات به صورت رو به جلو و عقب را بین لایهها فراهم میآورد و به این ترتیب، الگوهای پیچیدهتری در دادهها شناسایی میشوند.
انواع خاصی از شبکههای عصبی مصنوعی عبارتند از:
شبکههای عصبی پیشخور (Feed-forward neural networks)
شبکههای عصبی پیشخور، سادهترین نوع شبکههای عصبی مصنوعی هستند که در آن اطلاعات تنها در یک جهت، از لایه ورودی به سمت لایه خروجی، جریان مییابد. این شبکهها ممکن است شامل یک یا چند لایه پنهان باشند که به مدل اجازه میدهد تا روابط پیچیدهتری بین دادهها را یاد بگیرد. شبکههای پیشخور به دلیل سادگی و توانایی در پردازش حجم بالای دادههای نویزی، در بسیاری از کاربردها از جمله تشخیص چهره و بینایی رایانهای مورد استفاده قرار میگیرند.
شبکههای عصبی بازگشتی (RNNs)
شبکههای عصبی بازگشتی (RNN) از نظر ماهیت پیچیدهتر هستند. این شبکه خروجیِ گرههای پردازش را ذخیره میکند و نتیجه را دوباره به مدل باز میگرداند. به این ترتیب مدل یاد میگیرد که خروجی یک لایه را پیشبینی کند. هر گره در مدل RNN به عنوان یک سلول حافظه عمل میکند و محاسبات و اجرای عملیات را ادامه میدهد. به بیان دیگر در شبکههای بازگشتی، خروجی یک لایه به عنوان ورودی به همان لایه یا لایه بعدی بازگردانده میشود، که این امر باعث ایجاد حلقههای بازگشتی در ساختار شبکه میشود. این ویژگی به شبکه اجازه میدهد تا وابستگیهای طولانیمدت بین دادهها را مدلسازی کند.
این شبکه عصبی با همان انتشار رو به جلو به عنوان یک شبکه پیشخور شروع میشود، سپس تمام اطلاعات پردازش شده را برای استفاده مجدد در آینده به خاطر میسپارد. اگر پیشبینی شبکه نادرست باشد، خود سیستم یاد میگیرد و در طول انتشار به عقب (backpropagation) به سمت پیشبینی صحیح کار میکند. این نوع شبکه عصبی مصنوعی به طور مکرر در پردازش زبان طبیعی، ترجمه ماشینی و تولید متن استفاده می شود.
شبکههای عصبی کانولوشنال (CNNs)
شبکههای عصابی کانولوشنال (CNN) یکی از محبوبترین مدلهای مورد استفاده امروزه هستند. این مدل محاسباتی از نوعی پرسپترونهای چندلایه استفاده میکند و حاوی یک یا چند لایه کانولوشنال است که میتواند به طور کاملا متصل یا ادغام شده باشد.
مدل CNN به ویژه در حوزه تشخیص تصویر محبوب است. این فناوری در بسیاری از پیشرفتهترین کاربردهای هوش مصنوعی از جمله تشخیص چهره، دیجیتالی کردن متن و پردازش زبان طبیعی (NLP) به کار رفته است. سایر موارد استفاده شامل تشخیص بازنویسی، پردازش سیگنال و طبقه بندی تصویر است.
شبکههای عصبی غیرمختلط (Deconvolutional neural networks)
شبکههای عصبی غیرمختلط از فرآیند معکوس مدل CNN استفاده میکنند. آنها سعی میکنند ویژگیها یا سیگنالهای از دست رفتهای را پیدا کنند که شاید در ابتدا برای وظیفه سیستم CNN کماهمیت در نظر گرفته میشدند. شبکههای غیرمختلط در کاربردهایی مانند تولید تصویر، جداسازی اشیاء و رمزنگاری تصاویر مورد استفاده قرار میگیرند.
شبکههای عصبی ماژولار (Modular neural networks)
شبکههای عصبی ماژولار حاوی چندین شبکه عصبی هستند که به طور جداگانه از یکدیگر کار میکنند. این شبکهها در طول فرآیند محاسباتی با هم ارتباط برقرار نمیکنند و در فعالیتهای هم اختلال ایجاد نمیکنند. در نتیجه، فرآیندهای محاسباتی پیچیده یا بزرگ را میتوان با کارآمدی بیشتری انجام داد.
مزایای شبکههای عصبی مصنوعی
شبکههای عصبی مصنوعی مزایای زیر را ارائه میدهند:
- قابلیت پردازش موازی: شبکههای عصبی مصنوعی از قابلیت پردازش موازی برخوردارند، به این معنی که شبکه میتواند بیش از یک کار را به طور همزمان انجام دهد.
- ذخیرهسازی اطلاعات: شبکههای عصبی مصنوعی اطلاعات را در کل شبکه ذخیره میکنند، نه فقط در یک پایگاه داده. این تضمین میکند که حتی اگر مقدار کمی از دادهها از یک مکان ناپدید شود، کل شبکه همچنان به کار خود ادامه میدهد.
- غیرخطی بودن: توانایی یادگیری و مدلسازی روابط غیرخطی و پیچیده به مدلسازی روابط دنیای واقعی بین ورودی و خروجی کمک میکند.
- تحمل خطا: شبکههای عصبی مصنوعی از تحمل خطا برخوردارند، به این معنی که خرابی یا نقص یک یا چند سلول شبکه عصبی مصنوعی مانع از تولید خروجی نمیشود.
- آسیب تدریجی: این بدان معناست که شبکه به جای اینکه در صورت بروز مشکل به طور لحظهای از کار بیفتد، به تدریج در طول زمان عملکردش ضعیف میشود.
- متغیرهای ورودی نامحدود: هیچ محدودیتی برای متغیرهای ورودی، مانند نحوه توزیع آنها، وجود ندارد.
- تصمیمگیری مبتنی بر مشاهده: یادگیری ماشین به این معنی است که شبکه عصبی مصنوعی میتواند از رویدادها یاد بگیرد و بر اساس مشاهدات تصمیمگیری کند.
- پردازش دادههای سازماندهینشده: شبکههای عصبی مصنوعی در سازماندهی مقادیر زیادی از دادهها از طریق پردازش، مرتبسازی و دستهبندی آنها بسیار عالی هستند.
- توانایی یادگیری روابط پنهان: شبکههای عصبی مصنوعی میتوانند روابط پنهان در دادهها را بدون نیاز به هیچ رابطه ثابتی یاد بگیرند. این بدان معناست که شبکههای عصبی مصنوعی میتوانند دادههای بسیار ناپایدار و واریانس غیرثابت را بهتر مدلسازی کنند.
- توانایی تعمیم دادهها: توانایی تعمیم و استنتاج روابط ندیده در دادههای جدید به این معنی است که شبکههای عصبی مصنوعی میتوانند خروجی دادههای جدید را پیشبینی کنند.
معایب شبکههای عصبی مصنوعی
در کنار مزایای متعدد، شبکههای عصبی مصنوعی معایبی نیز دارند، از جمله موارد زیر:
- کمبود قوانین: نبود قوانین برای تعیین ساختار مناسب شبکه به این معنی است که معماری مناسب شبکه عصبی مصنوعی تنها از طریق آزمون، خطا و تجربه قابل دستیابی است.
- وابستگی سختافزاری: نیاز به پردازندههایی با قابلیت پردازش موازی باعث میشود شبکههای عصبی وابسته به سختافزار باشند.
- ترجمه عددی: شبکه با اطلاعات عددی کار میکند، یعنی همه مسائل باید قبل از ارائه به شبکه عصبی مصنوعی به مقادیر عددی ترجمه شوند. حتی در مدلهای زبانی بزرگ نیز که مدل با جملات و کلمات سر و کار دارد، این جملات و کلمات توسط مدل به کوچکترین واحدها به نام توکن شکسته میشوند که این فرایند توکنایزیشن نامیده میشود و سپس برای هر توکن اعدادی اختصاص مییابند. شما همراهان عزیز فروشگاه اینترنتی هامیا میتوانید با مطالعهی مقالهی “رمزگشایی از دنیای هوش مصنوعی و LLM: از توکنها تا پنجرهها کانالی” به درک کاملی این فرایند برسید.
- عدم اعتماد: نبود توضیح پشت راهحلهای کاوششده یکی از بزرگترین معایب شبکههای عصبی مصنوعی است. عدم توانایی در توضیح چرایی یا چگونگی راهحل، منجر به عدم اعتماد به شبکه میشود.
- نتایج نادرست: شبکههای عصبی مصنوعی در صورت آموزش نادرست، اغلب میتوانند نتایج ناقص یا نادرستی تولید کنند.
- ماهیت جعبه سیاه: به دلیل مدل هوش مصنوعی جعبه سیاه آنها، درک چگونگی پیشبینی دادهها یا طبقهبندی دادهها توسط شبکههای عصبی میتواند چالشبرانگیز باشد.
تاریخچه و سیر تکامل شبکههای عصبی
تاریخچه شبکههای عصبی مصنوعی (Artificial Neural Networks) ریشه در نیمه قرن بیستم دارد و از آن زمان تاکنون شاهد تحولات شگرفی بوده است. در ادامه به بررسی مهمترین مراحل این سیر تکاملی میپردازیم:
- دهه ۱۹۴۰: بنیانگذاری مفهومی
در سال ۱۹۴۳، ریاضیدانانی همچون وارن مککالاک (McCulloch, Warren) و والتر پیتس (Walter Pitts) یک سیستم مدار الکتریکی ساختند که الگوریتمهای سادهای را اجرا میکرد و برای تقریب عملکرد مغز انسان در نظر گرفته شده بود. این مدل، پایه و اساس تحقیقات بعدی در حوزه شبکههای عصبی قرار گرفت.
- دهه ۱۹۵۰: تولد پرسپترون
در سال ۱۹۵۸، فرانک روزنبلات (Frank Rosenblatt)، روانشناس آمریکایی که پدر یادگیری عمیق نیز محسوب میشود، پرسپترون را ایجاد کرد، نوعی شبکه عصبی مصنوعی که قادر به یادگیری و قضاوت با تغییر وزنهای خود است. پرسپترون دارای یک لایه واحد از واحدهای محاسباتی بود و میتوانست با مسائل قابل تفکیک خطی برخورد کند. اگرچه پرسپترون در آن زمان محدودیتهایی داشت، اما نشان داد که شبکههای عصبی میتوانند در حل مسائل یادگیری ماشین کاربرد داشته باشند.
- دهه ۱۹۷۰: ظهور پس انتشار
پل ورباس (Paul Werbos)، دانشمند آمریکایی، روش پسانتشار را توسعه داد که آموزش شبکههای عصبی چندلایه را تسهیل میکرد. این امر با امکان تنظیم وزنها در سراسر شبکه بر اساس خطای محاسبه شده در لایه خروجی، یادگیری عمیق را ممکن کرد.
- دهه ۱۹۸۰: احیای شبکههای عصبی
دهه 1980 را میتوان دوره احیای مجدد علاقه به شبکههای عصبی دانست. جفری هینتون (Geoffrey Hinton)، روانشناس شناختی و دانشمند کامپیوتر، به همراه یان لهکان (Yann LeCun)، دانشمند کامپیوتر و گروهی از محققان همکار، به بررسی مفهوم اتصالگرایی (connectionism) پرداختند که بر این ایده تأکید دارد که فرآیندهای شناختی از طریق شبکههای به هم مرتبط واحدهای پردازش ساده پدیدار میشوند. این دوره، راه را برای شبکههای عصبی مدرن و یادگیری عمیق هموار کرد.
- دهه ۱۹۹۰: ظهور شبکههای عصبی با حافظه بلندمدت
در اواخر دهه 1990، با معرفی معماری LSTM توسط اشمیدهوبر (Jürgen Schmidhuber) و هوخرایتر (Sepp Hochreiter)، گامی بزرگ در جهت بهبود توانایی شبکههای عصبی در یادگیری وابستگیهای طولانیمدت برداشته شد. شبکههای LSTM، به واسطه مکانیسم دروازههای خود، قادر به حفظ اطلاعات برای مدت طولانیتری نسبت به شبکههای بازگشتی ساده هستند و به همین دلیل در پردازش زبانهای طبیعی و سریهای زمانی بسیار موفق بودهاند.
- دهه ۲۰۰۰: پیشرفت در یادگیری بدون نظارت با شبکههای بولتزمن محدود
جفری هینتون و همکارانش پیشگام در شبکههای بولتزمن محدود (RBM) شدند، نوعی شبکه عصبی مصنوعی مولد که امکان یادگیری بدون نظارت را فراهم میکند. RBMها راه را برای شبکههای عمیق و الگوریتمهای یادگیری عمیق باز کردند.
- دهه 2010: انقلاب یادگیری عمیق
تحقیقات در زمینه شبکههای عصبی در حدود سال 2010 سرعت بسیار زیادی گرفت. روند دادههای بزرگ، جایی که شرکتها حجم عظیمی از دادهها را جمعآوری میکنند و محاسبات موازی، به دانشمندان دادهها دادههای آموزشی و منابع محاسباتی مورد نیاز برای اجرای ANNهای پیچیده را داد. پیروزی شبکه AlexNet در رقابت ImageNet در سال 2012، نقطه عطفی در تاریخ یادگیری عمیق بود و توجه محققان و صنعت را به این حوزه جلب کرد.
- دهه 2020 و فراتر از آن
با پیشرفت در معماری، روشهای آموزش و کاربردها شبکههای عصبی همچنان در حال توسعه سریع هستند. محققان در حال بررسی ساختارهای جدید شبکه مانند ترنسفورمرها و شبکههای عصبی گراف هستند که در NLP و درک روابط پیچیده مهارت دارند. علاوه بر این، تکنیکهایی مانند یادگیری انتقال و یادگیری خود نظارتی، مدلها را قادر میسازند تا از مجموعه دادههای کوچکتری بیاموزند و در عین حال بهتر تعمیم یابند. این پیشرفتها در حال پیشبرد حوزههایی مانند مراقبتهای بهداشتی، وسایل نقلیه خودران و مدلسازی آب و هوا هستند.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





